
데이터 기반 서비스 개선 (3/3) - 수리 모델
데이터 시각화 에 이어 수리 모델을 만들어보려한다.
결론
데이터 시각화를 통해 얻은 인사이트를 가지고 수리 모델을 만들 수 있다. 이번 글에서 사용한 데이터는 작고 케이스의 범위가 작아 실제를 대변한다고 보기는 어렵다. 그렇지만 이 글을 통해 전달하고자 하는 것은 데이터를 시각화를 했을 때 알지못하는 정보를 알 수 있고 그를 통해 불편함과 개선 사항을 인공지능을 사용하던 특정 프로세스를 개선하던 개선할 수 있다는 것이다.
수리 모델의 목적
heic 확장자의 경우 다른 확장자와 달리 처리 시간이 오래 걸리는데 이를 사용자에게 대략적인 소요 시간을 알려주고 싶다.
파일 크기 -> 예상 소요 시간
dataset
| 파일 확장자 | 파일 크기 | 소요 시간 |
|---|---|---|
| heic | 1KB | 66.502125 ms |
| heic | 1KB | 12.717458 ms |
| heic | 1KB | 17.316291 ms |
| heic | 1KB | 16.713042 ms |
| heic | 1KB | 11.276375 ms |
| heic | 10KB | 57.897750 ms |
| heic | 10KB | 55.575125 ms |
| heic | 10KB | 55.619792 ms |
| heic | 10KB | 38.095417 ms |
| heic | 10KB | 124.311042 ms |
| heic | 100KB | 299.386291 ms |
| heic | 100KB | 297.992333 ms |
| heic | 100KB | 313.035583 ms |
| heic | 100KB | 317.248292 ms |
| heic | 100KB | 380.337875 ms |
| heic | 1024KB | 1643.269250 ms |
| heic | 1024KB | 1550.642375 ms |
| heic | 1024KB | 1906.674042 ms |
| heic | 1024KB | 1998.733583 ms |
| heic | 1024KB | 1913.552792 ms |
| heic | 1024KB | 1542.215417 ms |
| heic | 1024KB | 1923.614000 ms |
| heic | 1024KB | 1535.548708 ms |
| heic | 1024KB | 1989.447833 ms |
| heic | 1024KB | 1516.601208 ms |
| heic | 2048KB | 2055.574000 ms |
| heic | 2048KB | 2069.355000 ms |
| heic | 2048KB | 2088.670750 ms |
| heic | 2048KB | 2045.557917 ms |
| heic | 2048KB | 2071.679584 ms |
| heic | 3072KB | 2726.974125 ms |
| heic | 3072KB | 2770.204500 ms |
| heic | 3072KB | 2606.339750 ms |
| heic | 3072KB | 2768.159125 ms |
| heic | 3072KB | 2756.679709 ms |
| heic | 5120KB | 2232.661041 ms |
| heic | 5120KB | 2434.699209 ms |
| heic | 5120KB | 2292.026250 ms |
| heic | 5120KB | 2216.264750 ms |
| heic | 5120KB | 2199.494917 ms |
수리 모델 만들기
전처리
dataset = pd.read_csv("heic-image-process.csv")
dataset = dataset.drop(columns=['filename', 'epoch', 'size_with_unit', 'type', 'revision', 'extension'])
train test split
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('duration')
test_labels = test_features.pop('duration')
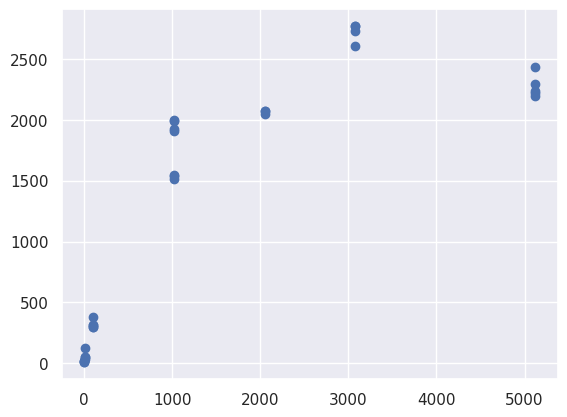
scatter
5MB 가 일 때 3MB 일 때보다 처리 속도가 빠른 것을 확인할 수 있다. 이것은 단순히 파일 크기가 처리 속도를 결정하지 않는다는 것을 의미한다. 더 많은 데이터 있으면 더 정확할 수 있겠으나 데이터가 적은 부분을 이해해주길 바란다.
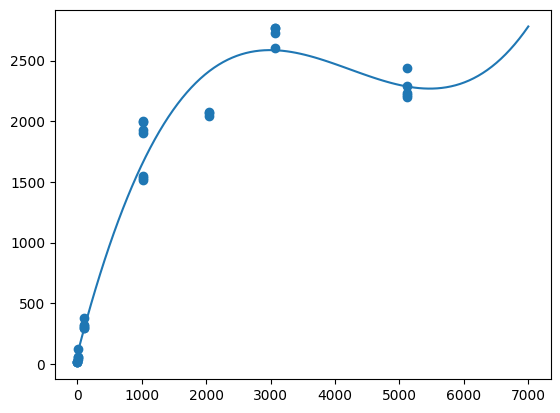
polynomial model
3차 함수를 만든다. x 는 size_kb 로 파일 크기를 가지고 있다. y 는 소요 시간이다.
import numpy
from sklearn.metrics import r2_score
x = train_features['size_kb']
y = train_labels
mymodel = numpy.poly1d(numpy.polyfit(x, y, 3))
1~7000 까지 100 개의 구간을 만든다.
myline = numpy.linspace(1, 7000, 100)
array([1.00000000e+00, 7.16969697e+01, 1.42393939e+02, 2.13090909e+02,
2.83787879e+02, 3.54484848e+02, 4.25181818e+02, 4.95878788e+02,
5.66575758e+02, 6.37272727e+02, 7.07969697e+02, 7.78666667e+02,
8.49363636e+02, 9.20060606e+02, 9.90757576e+02, 1.06145455e+03,
1.13215152e+03, 1.20284848e+03, 1.27354545e+03, 1.34424242e+03,
1.41493939e+03, 1.48563636e+03, 1.55633333e+03, 1.62703030e+03,
1.69772727e+03, 1.76842424e+03, 1.83912121e+03, 1.90981818e+03,
1.98051515e+03, 2.05121212e+03, 2.12190909e+03, 2.19260606e+03,
2.26330303e+03, 2.33400000e+03, 2.40469697e+03, 2.47539394e+03,
2.54609091e+03, 2.61678788e+03, 2.68748485e+03, 2.75818182e+03,
2.82887879e+03, 2.89957576e+03, 2.97027273e+03, 3.04096970e+03,
3.11166667e+03, 3.18236364e+03, 3.25306061e+03, 3.32375758e+03,
3.39445455e+03, 3.46515152e+03, 3.53584848e+03, 3.60654545e+03,
3.67724242e+03, 3.74793939e+03, 3.81863636e+03, 3.88933333e+03,
3.96003030e+03, 4.03072727e+03, 4.10142424e+03, 4.17212121e+03,
4.24281818e+03, 4.31351515e+03, 4.38421212e+03, 4.45490909e+03,
4.52560606e+03, 4.59630303e+03, 4.66700000e+03, 4.73769697e+03,
4.80839394e+03, 4.87909091e+03, 4.94978788e+03, 5.02048485e+03,
5.09118182e+03, 5.16187879e+03, 5.23257576e+03, 5.30327273e+03,
5.37396970e+03, 5.44466667e+03, 5.51536364e+03, 5.58606061e+03,
5.65675758e+03, 5.72745455e+03, 5.79815152e+03, 5.86884848e+03,
5.93954545e+03, 6.01024242e+03, 6.08093939e+03, 6.15163636e+03,
6.22233333e+03, 6.29303030e+03, 6.36372727e+03, 6.43442424e+03,
6.50512121e+03, 6.57581818e+03, 6.64651515e+03, 6.71721212e+03,
6.78790909e+03, 6.85860606e+03, 6.92930303e+03, 7.00000000e+03])
mymodel 에 1~7000 까지 100 개의 구간을 넣어 그래프를 그린다.
plt.plot(myline, mymodel(myline))
plt.scatter(train_features['size_kb'], train_labels)
test score
테스트 데이터 셋의 크기가 작지만 대략 0.95로 높은 점수를 보여주고 있다.
r2_score(test_labels, mymodel(test_features['size_kb'])) # 0.9480949433245521
수리 모델 확인
mymodel
# poly1d([ 4.17134985e-08, -5.29525806e-04, 2.04859364e+00, 7.94939140e+01])
1000KB 파일일 때
(1000 * (4.17134985e-08 ** 3)) + (1000 * (-5.29525806e-04 ** 2)) + (1000 * 2.04859364e+00) + 7.94939140e+01
# 2128.0872736024207