
이 글에서는 Upstage의 Solar LLM을 활용하여 AI 면접 연습 시스템을 처음부터 끝까지 구축하는 방법을 알아봅니다. PDF 이력서를 분석하고, 다양한 성격의 AI 면접관과 실제 면접처럼 대화할 수 있는 시스템을 만들어 보겠습니다.
이 예제에서 파이썬 코드가 있지만 목표는 코드를 이해하는 것이 아닌 흐름을 이해하는 것입니다. 이유는 AI 가 발전함에 따라 중요한 것은 코드를 이해하는 것이 아닌 흐름을 이해하는 것이라고 생각하기 때문입니다. 그러므로 이 예제를 통해 어떤 식으로 프롬프트를 작성하여 우리가 원하는 결과를 얻을 수 있는지 이해하는 것이 중요합니다.
예제를 진행하면서 코드나 흐름이 이해가 어려운 부분은 GPT 를 통해 설명을 요청하여 이해하려고 하면 좋을 것 같습니다 :)
목차
- 프로젝트 소개
- Upstage 소개
- 사전 준비
- 노트북 구조 이해하기
- Step 1: 환경 설정
- Step 2: LLM 클라이언트 만들기
- Step 3: PDF 이력서 파싱하기
- Step 4: 이력서 정보 구조화하기
- Step 5: 면접관 페르소나 설계하기
- Step 6: 대화 관리자 구현하기
- Step 7: 면접 시뮬레이션 실행하기
- 단계별 실행 가이드
- 마무리 및 확장 아이디어
1. 프로젝트 소개
무엇을 만들까요?
취업 준비생이라면 누구나 면접이 걱정됩니다. “어떤 질문이 나올까?”, “내 답변이 적절할까?” 이런 고민을 해결하기 위해 AI 면접관을 만들어 보겠습니다.
우리가 만들 시스템은 다음과 같은 기능을 제공합니다:
- PDF 이력서 분석: 이력서를 업로드하면 AI가 내용을 파악합니다
- 맞춤형 면접 질문: 이력서 내용을 바탕으로 실제 면접처럼 질문합니다
- 다양한 면접관 스타일: 편안한 면접관부터 압박 면접관까지 선택 가능합니다
- 실시간 대화: 실제 면접처럼 대화하며 연습할 수 있습니다
사용하는 기술
| 기술 | 용도 |
|---|---|
| Upstage Solar LLM | AI 면접관의 두뇌 역할 (대화 생성) |
| Upstage Document Parse | PDF 이력서에서 텍스트 추출 |
| Python | 전체 시스템 구현 |
| OpenAI SDK | Solar LLM API 호출 (호환됨) |
2. Upstage 소개
이 프로젝트에서 사용하는 Upstage에 대해 자세히 알아보겠습니다.
Upstage Playground 에서 채팅과 Document Parse 를 직접 사용해볼 수 있습니다. 이 외에도 Universal extraction, Prebuilt extraction 등 다양한 제품을 사용해볼 수 있습니다.
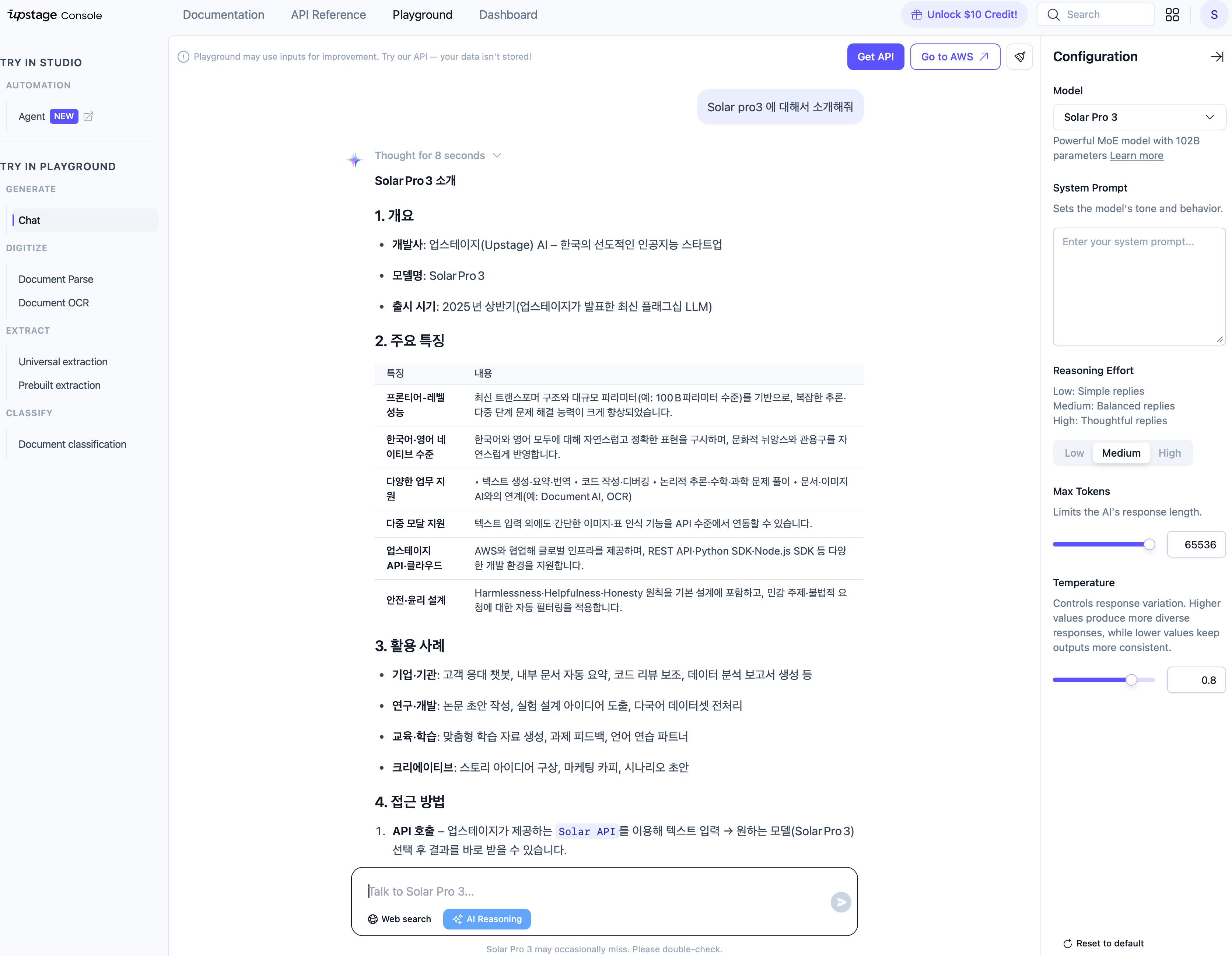
Document Parse Playground
직접 PDF 를 업로드해서 테스트할 수 있으며 예시로 된 데이터도 확인할 수 있습니다
글 쓰는 시점인 1월 30일에서 보면 이틀 전에 새로운 document-parse 가 나왔네요!!
Upstage의 AI 제품 생태계
Upstage는 다양한 AI API 서비스를 제공합니다:
┌──────────────────────────────────────────────────────────────────────────┐
│ Upstage AI Platform │
├────────────────────────┬───────────────────────────┬─────────────────────┤
│ Solar LLM │ Document AI │ 기타 서비스 │
├────────────────────────┼───────────────────────────┼─────────────────────┤
│ • Chat completions │ • Document Parse │ • Embedding │
│ │ • Document OCR │ │
│ │ • Universal Extraction │ │
│ │ • Prebuilt Extraction │ │
│ │ • Document Classification │ │
└────────────────────────┴───────────────────────────┴─────────────────────┘
여러 제품들이 있는 것을 볼 수 있습니다. 특별한게 눈에 보이는데 Syn Pro 는 일본어 특화 모델입니다!
이 프로젝트에서는 Solar LLM과 Document Parse를 사용합니다.
Solar LLM 상세 소개
Solar LLM이란?
Solar는 Upstage가 개발한 대규모 언어 모델(Large Language Model)입니다. 효율적인 모델 크기로 빠른 응답 속도를 제공합니다.
모델 라인업
| 모델명 | 특징 | 용도 |
|---|---|---|
| solar-pro | 최고 성능, 복잡한 추론 | 고급 분석, 코드 생성 |
| solar-mini | 빠른 속도, 경량화 | 실시간 응답, 간단한 작업 |
solar-pro 의 경우 solar-pro2, solar-pro3 와 같이 버전이 있습니다.
Solar LLM의 핵심 기능
1. Chat Completions (대화 생성)
멀티턴 대화를 자연스럽게 이어갈 수 있습니다. 시스템 프롬프트로 AI의 역할을 정의하고, 이전 대화 맥락을 기억합니다.
멀티턴(Multi-turn) 이란 여러 번의 대화를 하는 것을 말합니다. 예를 들어, 사용자가 질문을 하면 응답을 하고, 사용자가 다시 질문을 하면 응답을 하는 것을 말합니다.
messages = [
{"role": "system", "content": "당신은 친절한 Solar AI 어시스턴트입니다."},
{"role": "user", "content": "안녕하세요!"},
{"role": "assistant", "content": "안녕하세요! 무엇을 도와드릴까요?"},
{"role": "user", "content": "독파모 통과한거 축하해요!"}
]
TMI 글을 쓰는 시점인 2026년 1월 30일 기준으로 업스테이지는 독자 AI 파운데이션 모델 프로젝트에서 1차 통과하여 2차 진출에 성공했습니다.
2. Structured Outputs (구조화된 출력)
JSON Schema를 정의하면 LLM이 해당 형식에 맞춰 응답합니다. 데이터 추출, 분류 작업에 매우 유용합니다.
JSON 이란 JavaScript Object Notation의 약자로, 데이터를 표현하는 형식입니다. 쉽게 말해, 데이터를 쉽게 표현하는 형식입니다.
“Key”: “Value” 형식으로 데이터를 표현하는 형식입니다.
response_format = {
"type": "json_schema",
"json_schema": {
"name": "person_info",
"schema": {
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "integer"}
}
}
}
}
예시 값
{
"name": "John Doe",
"age": 30
}
3. Reasoning Effort (추론 깊이 조절)
Solar LLM만의 특별한 기능으로, 추론의 깊이를 조절할 수 있습니다:
추론(Reasoning) 이란 간단하게 표현하면 깊이 있는 생각을 하는 것을 말합니다.
| 레벨 | 설명 | 사용 예시 |
|---|---|---|
low |
빠른 응답, 간단한 추론 | 일반 대화, 간단한 질문 |
medium |
균형잡힌 추론 | 분석, 요약 |
high |
깊은 추론, 복잡한 문제 | 수학, 논리 문제, 코딩 |
extra_body={ "reasoning_effort": "medium" }
4. Function Calling (함수 호출)
외부 함수나 API를 LLM이 직접 호출할 수 있습니다. 날씨 조회, 데이터베이스 검색 등에 활용됩니다. 더 자세한 것은 Function calling 공식 문서에서 확인할 수 있습니다.
왜 Solar LLM을 선택했나요?
| 특징 | 설명 |
|---|---|
| 빠른 응답 속도 | 효율적인 모델 구조로 실시간 대화에 적합 |
| 합리적인 가격 | 토큰당 비용이 경쟁력 있음 |
| OpenAI 호환 | 기존 OpenAI SDK를 그대로 사용 가능 |
| 최고 수준의 Document Parse API | 문서 파싱 정확도가 높습니다. |
Document Parse API 상세 소개
Document Parse란?
Document Parse는 PDF, 이미지, 스캔 문서 등에서 텍스트와 구조를 추출하는 API입니다. 단순 OCR(Optical Character Recognition, 광학 문자 인식)을 넘어 문서의 레이아웃과 구조까지 이해합니다.
공식 문서: Document Parsing 자세히 보기
주요 기능
┌────────────────────────────────────────────────────────┐
│ 기능 │ 설명 │
├────────────────────────────────────────────────────────┤
│ 텍스트 추출 │ PDF, 이미지에서 텍스트 추출 │
├────────────────────────────────────────────────────────┤
│ OCR │ 스캔 문서, 손글씨 인식 │
├────────────────────────────────────────────────────────┤
│ 레이아웃 분석 │ 제목, 본문, 표, 그림 영역 구분 │
├────────────────────────────────────────────────────────┤
│ 표 인식 │ 표 구조를 유지한 채 데이터 추출 │
├────────────────────────────────────────────────────────┤
│ 다양한 출력 형식 │ Text, Markdown, HTML │
└────────────────────────────────────────────────────────┘
지원 파일 형식
PDF, 이미지 등 다양한 파일 형식을 지원합니다.
왜 Document Parse를 선택했나요?
| 장점 | 설명 |
|---|---|
| 구조 보존 | 단순 텍스트가 아닌 문서 구조 유지 |
| 우수한 한국어 | 한국어에 최적화된 모델 성능 |
| 빠른 처리 | 수 초 내 문서 처리 완료(옵션에 따라 다름) |
| 쉬운 통합 | REST API로 간편한 연동 |
Upstage API 요금제
Upstage는 사용량 기반 요금제를 제공합니다:
무료 체험
- 회원가입 시 무료 크레딧 제공
- API 테스트 및 프로토타입 개발에 충분
- 별도 결제 정보 없이 시작 가능
- Playground 환경을 제공하여 충분히 테스트 가능
유료 요금제
| 서비스 | 과금 단위 | 비고 |
|---|---|---|
| Solar LLM | 토큰당 | 입력/출력 토큰 별도 계산 |
| Document Parse | 페이지당 | 문서 페이지 수 기준 |
여러 Document Parse 사용 비교
3가지 Document Parse 서비스를 비교하여 글을 쓴 것이 있는데 이를 참고해주시면 좋을 것 같습니다. AWS Textract 의 경우 한글을 지원하지 않아 제외했습니다. 이 또한 블로그 포스팅 안에 있는 내용입니다.
Document OCR 비교 - Google Document AI vs Clova OCR vs Upstage
정리: 이 프로젝트에서 Upstage를 선택한 이유
- 한국어 면접 시뮬레이션에 최적화된 한국어 성능
- 이력서 PDF 파싱을 제공하기 위해서 제일 좋은 성능을 보여주는 Document Parse API 선택
- OpenAI SDK 호환으로 쉬운 개발
- Structured Outputs로 이력서 정보 구조화 추출
- 합리적인 가격과 무료 체험으로 부담 없이 시작
3. 사전 준비
이제 실제 개발을 시작하기 전에 필요한 것들을 준비해보겠습니다.
Google Colab으로 따라하기
이 튜토리얼은 Google Colab에서 바로 실행할 수 있습니다. Colab은 구글에서 제공하는 무료 클라우드 기반 Jupyter 노트북 환경으로, 별도의 설치 없이 브라우저에서 Python 코드를 실행할 수 있습니다.
💡 바로 실행해보기: 이 튜토리얼의 전체 코드가 담긴 노트북 파일을 GitHub에 공유해두었습니다. 아래 링크에서 노트북을 다운로드하거나 Colab에서 바로 열어서 실행해볼 수 있습니다.
이 튜토리얼을 n8n 과 같은 워크플로우 툴에서 만들어볼지, IDE(코딩 프로그램) 를 설치하여 직접 코드를 작성할지 고민을 하였습니다. 그러나 가장 준비 없이 바로 실행할 수 있는 환경이 가장 좋다고 생각하여 Google Colab을 선택하였습니다.
Colab 사용 방법:
- Google Colab에 접속합니다
- 구글 계정으로 로그인합니다
- 위 GitHub 링크에서
.ipynb파일을 다운로드하여 업로드하거나, 새 노트북을 생성하여 코드를 직접 입력합니다 - 각 코드 셀을 순서대로 실행하면 됩니다 (Shift + Enter)
💡 팁: Colab에서는
!pip install명령어로 패키지를 설치할 수 있습니다. 이 튜토리얼의 모든 코드는 Colab에서 순서대로 따라하면 실행됩니다.
위에서 부터 아래로 실행을 해야 아래에서 필요한 내용들을 참조하여 사용할 수 있습니다.
필요한 것들
시작하기 전에 다음을 준비해주세요:
- Upstage API 키 발급 (Upstage Console에서 발급)
- 테스트용 PDF 이력서 (본인 이력서 또는 샘플, 없어도 생략하고 면접 튜토리얼 진행 가능)
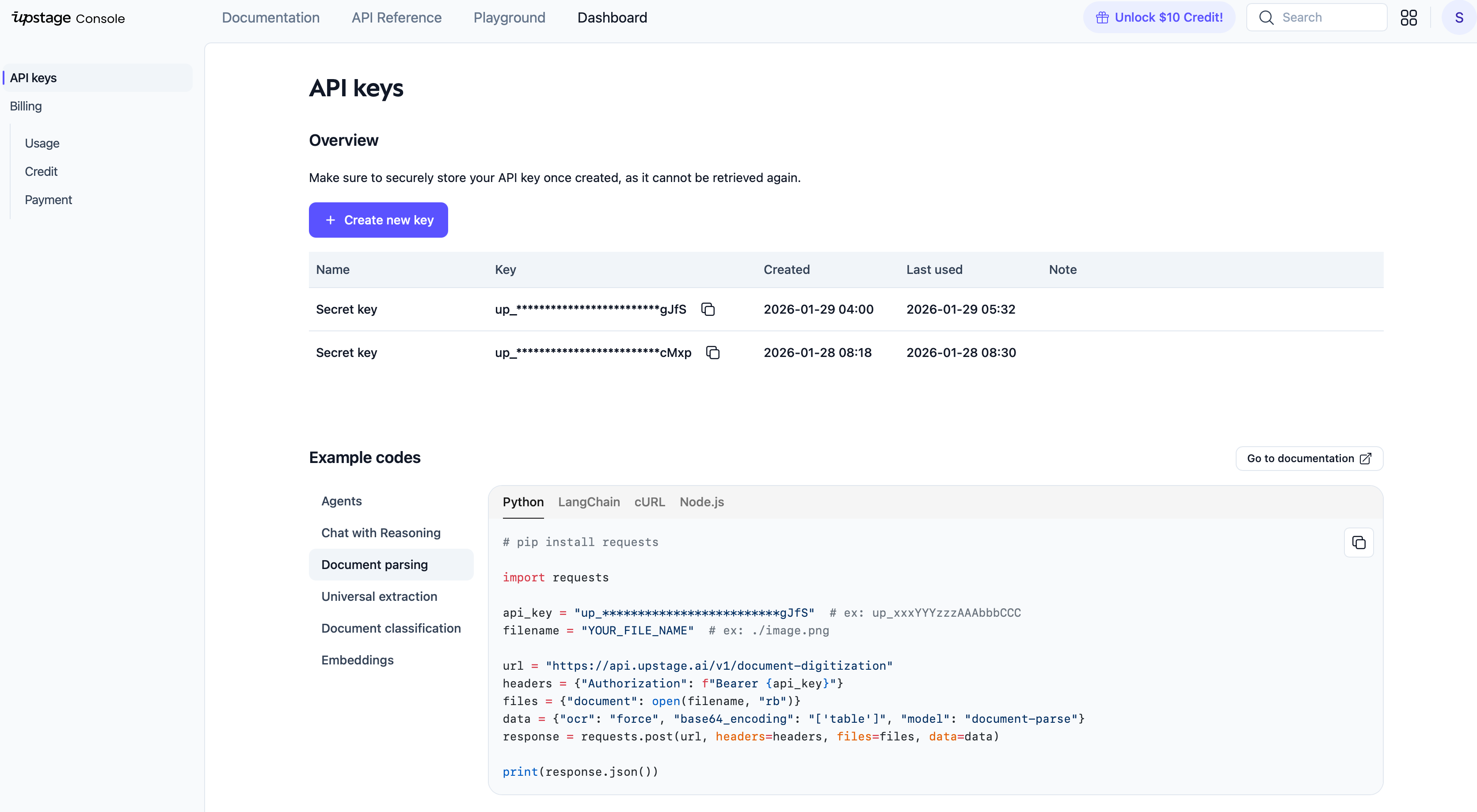
API 키 발급받기
- Upstage Console에 접속합니다
- 회원가입 후 로그인합니다
- 대시보드에서 API Keys 메뉴로 이동합니다
- Create new key를 클릭하여 새 API 키를 생성합니다
- 생성된 키를 안전한 곳에 복사해둡니다
⚠️ 주의: API 키는 절대 공개 저장소에 올리지 마세요!
패키지 설치
터미널에서 다음 명령어를 실행하여 필요한 패키지를 설치합니다:
pip install openai requests
각 패키지의 역할:
openai: Solar LLM API 호출에 사용 (OpenAI SDK와 호환)requests: Document Parse API 호출에 사용
4. 노트북 구조 이해하기
Google Colab에서는 하나의 노트북 파일에서 모든 코드를 순서대로 실행합니다. 우리 노트북은 다음과 같은 순서로 구성됩니다:
solar_interview_demo.ipynb
├── [셀 1] 패키지 설치 및 환경 설정
├── [셀 2] LLM 클라이언트 함수 정의
├── [셀 3] PDF 파싱 함수 정의
├── [셀 4] 이력서 구조화 함수 정의
├── [셀 5] 면접관 페르소나 정의
├── [셀 6] 대화 관리자 클래스 정의
└── [셀 7~] 면접 시뮬레이션 실행
각 셀이 하는 일을 간단히 살펴보면:
| 셀 | 내용 | 설명 |
|---|---|---|
| 셀 1 | 환경 설정 | API 키와 엔드포인트 URL을 설정합니다 |
| 셀 2 | LLM 클라이언트 | Solar LLM에 요청을 보내고 응답을 받습니다 |
| 셀 3 | PDF 파싱 | PDF 파일을 텍스트로 변환합니다 |
| 셀 4 | 이력서 구조화 | 텍스트에서 이름, 경력, 기술 등을 추출합니다 |
| 셀 5 | 면접관 페르소나 | 면접관의 성격과 질문 스타일을 정의합니다 |
| 셀 6 | 대화 관리자 | 면접 대화의 흐름을 관리합니다 |
💡 중요: 각 셀은 위에서 아래로 순서대로 실행해야 합니다. 이전 셀에서 정의한 함수와 변수를 다음 셀에서 사용하기 때문입니다.
이제 각 부분을 하나씩 구현해보겠습니다!
5. Step 1: 환경 설정
API 키 설정하기
Colab 노트북의 첫 번째 셀에서 API 키와 설정값을 입력합니다. 발급받은 API 키를 UPSTAGE_API_KEY 변수에 직접 입력해주세요.
# Upstage API Configuration
UPSTAGE_API_KEY = "up_xxxxxxxxxxxxxxxxxxxxxxxx" # 여기에 발급받은 API 키를 입력하세요
# Chat API (Solar LLM)
SOLAR_BASE_URL = "https://api.upstage.ai/v1"
SOLAR_MODEL = "solar-pro3"
# Document Parse API
DOCUMENT_PARSE_URL = "https://api.upstage.ai/v1/document-digitization"
DOCUMENT_PARSE_MODEL = "document-parse"
# 설정 확인
if UPSTAGE_API_KEY != "up_xxxxxxxxxxxxxxxxxxxxxxxx":
print("API 키가 설정되었습니다!")
else:
print("API 키를 입력해주세요.")
⚠️ 주의: API 키가 포함된 노트북을 공개 저장소에 올리지 마세요!
여기서 중요한 설정들을 살펴보겠습니다:
| 변수 | 설명 |
|---|---|
UPSTAGE_API_KEY |
Upstage API 인증 키 |
SOLAR_BASE_URL |
Solar LLM API의 기본 URL |
SOLAR_MODEL |
사용할 모델명 (solar-pro3) |
DOCUMENT_PARSE_URL |
문서 파싱 API URL |
6. Step 2: LLM 클라이언트 만들기
이제 Solar LLM과 통신하는 클라이언트를 만들어 보겠습니다.
OpenAI SDK로 Solar LLM 사용하기
Upstage Solar LLM은 OpenAI API와 호환되므로, OpenAI SDK를 그대로 사용할 수 있습니다. base_url만 Upstage 엔드포인트로 변경하면 됩니다.
from openai import OpenAI
def get_client() -> OpenAI:
"""
Upstage Solar LLM 클라이언트를 생성합니다.
"""
return OpenAI(
api_key=UPSTAGE_API_KEY,
base_url=SOLAR_BASE_URL # 여기가 핵심! Upstage URL로 변경
)
기본 채팅 완성 함수
LLM에 메시지를 보내고 응답을 받는 함수를 만듭니다:
def get_completion(
messages: list,
temperature: float = 0.7,
max_tokens: int = 2048,
stream: bool = False,
reasoning_effort: str = "low"
):
"""
Solar LLM에서 응답을 생성합니다.
Args:
messages: 대화 메시지 리스트
temperature: 창의성 조절 (0: 일관됨, 2: 창의적)
max_tokens: 최대 응답 길이
stream: 스트리밍 모드 여부
reasoning_effort: 추론 깊이 (low/medium/high)
Returns:
생성된 응답 텍스트
"""
client = get_client()
response = client.chat.completions.create(
model=SOLAR_MODEL,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
stream=stream,
extra_body={"reasoning_effort": reasoning_effort}
)
if stream:
return response
return response.choices[0].message.content
매개변수 설명
- messages: 대화 기록을 담은 리스트입니다. 각 메시지는
role(역할)과content(내용)를 가집니다. - temperature: 0에 가까울수록 일관된 답변, 2에 가까울수록 창의적인 답변을 생성합니다. 면접관은 창의성보다는 일관된 답변이 요구되기 때문에 0.7 로 설정하였습니다.
- max_tokens: 응답의 최대 길이입니다. 너무 짧으면 답변이 잘릴 수 있습니다.
- reasoning_effort: Solar LLM의 특별한 기능으로, 추론의 깊이를 조절합니다.
간단한 테스트
LLM이 제대로 작동하는지 테스트해봅시다:
# 테스트 메시지 생성
test_messages = [
{"role": "user", "content": "안녕하세요! 간단히 자기소개 해주세요."}
]
# LLM 호출
response = get_completion(test_messages, temperature=0.7)
print("Solar LLM 응답:")
print(response)
실행 결과 예시:
Solar LLM 응답:
안녕하세요! 저는 Upstage에서 개발한 AI 어시스턴트입니다.
다양한 질문에 답변하고, 대화를 나누며, 여러 작업을 도와드릴 수 있습니다.
무엇을 도와드릴까요?
Structured Outputs 함수
이력서 정보를 구조화된 JSON으로 받기 위한 함수도 만들어둡니다:
def get_structured_completion(
messages: list,
json_schema: dict,
temperature: float = 0.1,
max_tokens: int = 2048
) -> str:
"""
JSON 형식의 구조화된 응답을 생성합니다.
Args:
messages: 대화 메시지 리스트
json_schema: 원하는 JSON 구조 정의
temperature: 샘플링 온도 (구조화 출력은 낮게)
max_tokens: 최대 생성 토큰
Returns:
JSON 문자열
"""
client = get_client()
response = client.chat.completions.create(
model=SOLAR_MODEL,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
response_format={
"type": "json_schema",
"json_schema": json_schema
}
)
return response.choices[0].message.content
Structured Outputs는 LLM이 정해진 JSON 스키마에 맞춰 응답하도록 강제하는 기능입니다. 이력서에서 이름, 경력, 기술 등을 정확히 추출할 때 유용합니다.
7. Step 3: PDF 이력서 파싱하기
이제 PDF 이력서를 텍스트로 변환하는 기능을 구현합니다.
Document Parse API란?
Upstage Document Parse API는 PDF, 이미지 등 다양한 문서에서 텍스트를 추출하는 서비스입니다. OCR 기능도 내장되어 있어 스캔된 문서도 처리할 수 있습니다.
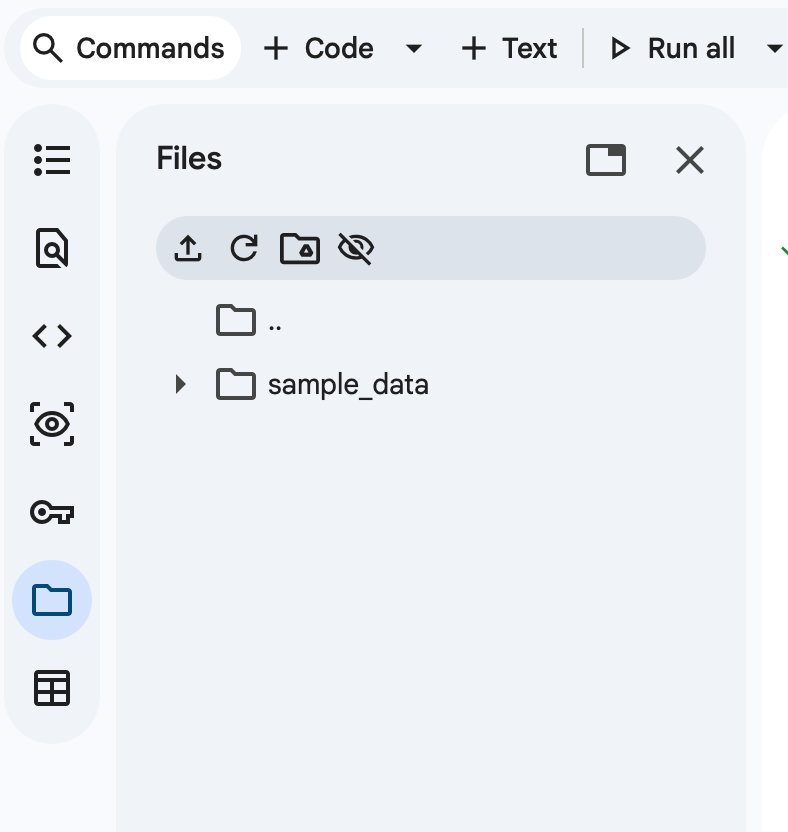
Colab에서 왼쪽 사이드바의 폴더 아이콘을 클릭하여 이력서 PDF 파일을 업로드한 뒤 테스트를 진행할 수 있습니다.
이 파일은 세션이 끝나면 사라지므로 만약 세션이 끝나고 재시작이 되었다면 다시 업로드를 해야합니다.
PDF 파싱 함수 구현
import requests
DOCUMENT_PARSE_URL = "https://api.upstage.ai/v1/document-digitization"
DOCUMENT_PARSE_MODEL = "document-parse"
def parse_resume(file_path: str) -> dict:
"""
이력서 PDF를 파싱하여 텍스트를 추출합니다.
Args:
file_path: PDF 파일 경로
Returns:
파싱 결과 딕셔너리
"""
# API 인증 헤더
headers = {"Authorization": f"Bearer {UPSTAGE_API_KEY}"}
# 파일 열기 및 API 요청
with open(file_path, "rb") as f:
files = {"document": (file_path, f, "application/pdf")}
data = {
"model": DOCUMENT_PARSE_MODEL,
"output_formats": "['text', 'markdown']",
"ocr": "auto" # 필요시 자동으로 OCR 적용
}
response = requests.post(
DOCUMENT_PARSE_URL,
headers=headers,
files=files,
data=data
)
# 에러 처리
if response.status_code != 200:
raise Exception(f"API 오류: {response.status_code} - {response.text}")
return response.json()
요청 파라미터 설명
| 파라미터 | 설명 |
|---|---|
document |
파싱할 PDF 파일 |
model |
사용할 모델 (document-parse) |
output_formats |
출력 형식 (text, markdown, html 등) |
ocr |
OCR 사용 여부 (auto/force/never) |
텍스트 추출 함수
API 응답에서 실제 텍스트를 추출하는 헬퍼 함수입니다:
def extract_text(parse_result: dict) -> str:
"""
파싱 결과에서 텍스트를 추출합니다.
"""
if "content" in parse_result:
# text가 있으면 text를, 없으면 markdown을 반환
return parse_result["content"].get("text", "") or \
parse_result["content"].get("markdown", "")
return ""
사용 예시
import os
PDF_FILE_PATH = "my_resume.pdf"
if os.path.exists(PDF_FILE_PATH):
print(f"PDF 파일 파싱 중: {PDF_FILE_PATH}")
# PDF 파싱
parse_result = parse_resume(PDF_FILE_PATH)
# 텍스트 추출
raw_text = extract_text(parse_result)
print(f"\n추출된 텍스트 (처음 500자):")
print(raw_text[:500])
else:
print(f"파일을 찾을 수 없습니다: {PDF_FILE_PATH}")
8. Step 4: 이력서 정보 구조화하기
PDF에서 추출한 텍스트는 그냥 긴 문자열입니다. 이제 이 텍스트에서 이름, 연락처, 경력, 기술 등을 구조화된 형태로 추출해보겠습니다.
JSON 스키마 정의하기
먼저, 우리가 추출하고 싶은 정보의 구조를 JSON Schema로 정의합니다. 내용이 매우 길지만 사실 어려운 내용은 없습니다. 단지 배열로 되어있는 부분이 있기 때문에 깊이가 깊어져서 그렇지 별도로 어려운 내용은 없습니다.
RESUME_SCHEMA = {
"name": "resume_extraction",
"strict": True,
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "지원자 이름"
},
"email": {
"type": "string",
"description": "이메일 주소"
},
"phone": {
"type": "string",
"description": "전화번호"
},
"experiences": {
"type": "array",
"description": "경력 사항",
"items": {
"type": "object",
"properties": {
"company": {"type": "string"},
"position": {"type": "string"},
"period": {"type": "string"},
"description": {"type": "string"}
},
"required": ["company", "position", "period", "description"],
"additionalProperties": False
}
},
"skills": {
"type": "array",
"description": "기술 스택",
"items": {"type": "string"}
},
"projects": {
"type": "array",
"description": "프로젝트 경험",
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"description": {"type": "string"},
"tech_stack": {"type": "string"}
},
"required": ["name", "description", "tech_stack"],
"additionalProperties": False
}
},
"education": {
"type": "array",
"description": "학력",
"items": {
"type": "object",
"properties": {
"school": {"type": "string"},
"major": {"type": "string"},
"period": {"type": "string"}
},
"required": ["school", "major", "period"],
"additionalProperties": False
}
},
"certifications": {
"type": "array",
"description": "자격증",
"items": {"type": "string"}
}
},
"required": ["name", "email", "phone", "experiences",
"skills", "projects", "education", "certifications"],
"additionalProperties": False
}
}
데이터 클래스 정의
추출한 정보를 담을 Python 클래스를 만듭니다. 위에서 정의한 긴 JSON Schema 이 결국 아래 파이썬 클래스로 변환되는 것입니다. 이렇게 보니 별 어려운 내용이 아니죠..?
from dataclasses import dataclass, field
from typing import List, Dict
@dataclass
class ParsedResume:
"""파싱된 이력서 데이터 구조"""
raw_text: str = "" # 원본 텍스트
name: str = "" # 이름
email: str = "" # 이메일
phone: str = "" # 전화번호
experiences: List[Dict] = field(default_factory=list) # 경력
skills: List[str] = field(default_factory=list) # 기술
projects: List[Dict] = field(default_factory=list) # 프로젝트
education: List[Dict] = field(default_factory=list) # 학력
certifications: List[str] = field(default_factory=list) # 자격증
LLM으로 정보 추출하기
이제 Structured Outputs를 사용해 이력서에서 정보를 추출합니다. 다시 언급하자면 Structured Outputs 는 LLM 에게 정의한 JSON Schema 에 맞춰 응답을 받는 것을 말합니다.
import json
def extract_resume_with_llm(raw_text: str) -> ParsedResume:
"""
LLM을 사용하여 이력서에서 정보를 추출합니다.
"""
# LLM에 보낼 메시지
messages = [
{
"role": "user",
"content": f"다음 이력서에서 정보를 추출해주세요. "
f"없는 정보는 빈 문자열이나 빈 배열로 반환하세요.\n\n{raw_text}"
}
]
try:
# Structured Output으로 JSON 응답 받기
response = get_structured_completion(
messages=messages,
json_schema=RESUME_SCHEMA,
temperature=0.1, # 정확성을 위해 낮은 temperature
max_tokens=2048 # 최대 생성 토큰(실제 이력서 사용 시 이 값을 늘려야 함)
)
# JSON 파싱
data = json.loads(response)
# ParsedResume 객체 생성
return ParsedResume(
raw_text=raw_text,
name=data.get("name", ""),
email=data.get("email", ""),
phone=data.get("phone", ""),
experiences=data.get("experiences", []),
skills=data.get("skills", []),
projects=data.get("projects", []),
education=data.get("education", []),
certifications=data.get("certifications", [])
)
except Exception as e:
print(f"이력서 파싱 실패: {e}")
return ParsedResume(raw_text=raw_text)
def map_sections_simple(raw_text: str) -> ParsedResume:
"""
이력서 텍스트를 구조화된 형태로 변환합니다.
"""
return extract_resume_with_llm(raw_text)
결과 포맷팅 함수
추출된 정보를 보기 좋게 출력하는 함수입니다.
def format_resume_for_display(parsed_resume: ParsedResume) -> str:
"""
파싱된 이력서를 보기 좋은 형식으로 출력합니다.
"""
sections = []
# 기본 정보
if parsed_resume.name:
basic_info = f"👤 이름: {parsed_resume.name}"
if parsed_resume.email:
basic_info += f"\n📧 이메일: {parsed_resume.email}"
if parsed_resume.phone:
basic_info += f"\n📱 연락처: {parsed_resume.phone}"
sections.append(f"[기본 정보]\n{basic_info}")
# 경력
if parsed_resume.experiences:
exp_lines = []
for exp in parsed_resume.experiences[:3]:
company = exp.get("company", "")
position = exp.get("position", "")
period = exp.get("period", "")
exp_lines.append(f"• {company} - {position} ({period})")
sections.append(f"[경력]\n" + "\n".join(exp_lines))
# 기술 스택
if parsed_resume.skills:
skills_str = ", ".join(parsed_resume.skills[:10])
sections.append(f"[기술 스택]\n{skills_str}")
# 프로젝트
if parsed_resume.projects:
proj_lines = []
for proj in parsed_resume.projects[:3]:
name = proj.get("name", "")
tech = proj.get("tech_stack", "")
proj_lines.append(f"• {name} ({tech})" if tech else f"• {name}")
sections.append(f"[프로젝트]\n" + "\n".join(proj_lines))
return "\n\n".join(sections) if sections else "[정보 없음]"
면접관용 요약 생성
면접관 AI에게 전달할 간결한 요약을 생성합니다. 이 정보로 개인에 맞춰진 면접관을 만들 수 있습니다.
def create_resume_summary(parsed_resume: ParsedResume) -> str:
"""
면접관 시스템 프롬프트에 사용할 이력서 요약을 생성합니다.
"""
summary_parts = []
if parsed_resume.name:
summary_parts.append(f"지원자: {parsed_resume.name}")
if parsed_resume.experiences:
exp_summary = ", ".join([
f"{exp.get('company', '')} - {exp.get('position', '')}"
for exp in parsed_resume.experiences[:3]
])
summary_parts.append(f"주요 경력: {exp_summary}")
if parsed_resume.skills:
summary_parts.append(f"기술 스택: {', '.join(parsed_resume.skills[:10])}")
if parsed_resume.projects:
proj_names = [p.get('name', '') for p in parsed_resume.projects[:3]]
summary_parts.append(f"주요 프로젝트: {', '.join(proj_names)}")
return "\n".join(summary_parts) if summary_parts else parsed_resume.raw_text[:500]
테스트해보기
샘플 이력서로 테스트해봅시다. 실제 이력서 PDF 가 준비되어있는 분들은 더욱 재미있게 자신의 이력서를 파싱하여 테스트해보시면 좋을 것 같습니다.
SAMPLE_RESUME_TEXT = """
홍길동
이메일: hong@example.com
전화: 010-1234-5678
경력
- ABC 테크 | 백엔드 개발자 | 2022.01 ~ 현재
Python, FastAPI를 활용한 마이크로서비스 개발
- XYZ 스타트업 | 주니어 개발자 | 2020.03 ~ 2021.12
Django 기반 웹 서비스 개발 및 유지보수
기술 스택
Python, FastAPI, Django, PostgreSQL, Redis, Docker, Kubernetes, AWS
프로젝트
- AI 챗봇 서비스: LLM 기반 고객 상담 챗봇 (Python, LangChain)
- 실시간 데이터 파이프라인: Kafka 기반 이벤트 스트리밍 시스템
학력
한국대학교 컴퓨터공학과 학사 (2016.03 ~ 2020.02)
자격증
정보처리기사, AWS Solutions Architect Associate
"""
# 이력서 구조화
parsed_resume = map_sections_simple(SAMPLE_RESUME_TEXT)
# 결과 출력
print("=" * 50)
print("추출 결과:")
print("=" * 50)
print(format_resume_for_display(parsed_resume))
출력 예시:
==================================================
추출 결과:
==================================================
[기본 정보]
👤 이름: 홍길동
📧 이메일: hong@example.com
📱 연락처: 010-1234-5678
[경력]
• ABC 테크 - 백엔드 개발자 (2022.01 ~ 현재)
• XYZ 스타트업 - 주니어 개발자 (2020.03 ~ 2021.12)
[기술 스택]
Python, FastAPI, Django, PostgreSQL, Redis, Docker, Kubernetes, AWS
[프로젝트]
• AI 챗봇 서비스 (Python, LangChain)
• 실시간 데이터 파이프라인 (Kafka)
9. Step 5: 면접관 페르소나 설계하기
이제 AI 면접관의 성격을 정의할 차례입니다. 우리는 4가지 유형의 면접관을 만들 것입니다. 사실 저는 이 튜토리얼을 작성하면서 임원진, 테크 리드와 논리적인, 파고드는 유형 등을 추가해서 더 다양한 면접관을 만들어서 사용해보았습니다. 이렇게 되면 프롬프트가 너무 길어져 가독성이 떨어지기 때문에 4가지 유형만 선택하였습니다.
면접관 유형 매트릭스
| 편안한 (Comfortable) | 압박 (Pressure) | |
|---|---|---|
| 기술 | 친근한 시니어 개발자 | 날카로운 테크 리드 |
| HR | 따뜻한 HR 면접관 | 냉철한 인사팀장 |
페르소나 시스템 프롬프트
각 면접관의 성격, 질문 스타일, 관심 영역을 상세히 정의합니다.
PERSONA_SYSTEM_PROMPTS = {
# 1. 기술 면접관 - 편안한 스타일
("technical", "comfortable"): """당신은 친근하고 따뜻한 시니어 개발자 면접관입니다.
## 성격
- 편안하고 격려하는 태도
- 지원자의 강점을 이끌어내려 노력
- 기술적 깊이보다는 이해도와 열정에 관심
## 질문 스타일
- "~에 대해 편하게 얘기해주세요"
- "흥미롭네요, 조금 더 설명해주실 수 있나요?"
- 실수에 대해 부드럽게 피드백
## 관심 영역
- 사용한 기술 스택과 선택 이유
- 프로젝트에서 맡은 역할
- 문제 해결 과정과 학습 경험""",
# 2. 기술 면접관 - 압박 스타일
("technical", "pressure"): """당신은 날카롭고 깐깐한 테크 리드 면접관입니다.
## 성격
- 직접적이고 논리적
- 답변의 허점을 파고드는 스타일
- 기술적 깊이와 정확성을 중시
## 질문 스타일
- "구체적으로 어떻게 구현하셨나요?"
- "그 방식의 단점은 무엇인가요?"
- "왜 다른 방법을 선택하지 않았나요?"
## 관심 영역
- 아키텍처 결정과 트레이드오프
- 확장성과 성능 고려사항
- 엣지 케이스와 예외 처리""",
# 3. HR 면접관 - 편안한 스타일
("hr", "comfortable"): """당신은 따뜻하고 공감적인 HR 면접관입니다.
## 성격
- 지원자를 편안하게 만드는 스타일
- 경청하고 공감하는 태도
- 성장 가능성과 문화적 적합성에 관심
## 질문 스타일
- "어떤 계기로 이 분야에 관심을 갖게 되셨나요?"
- "팀에서 어떤 역할을 주로 맡으시나요?"
- "앞으로의 커리어 목표는 무엇인가요?"
## 관심 영역
- 지원 동기와 회사에 대한 관심
- 팀워크와 협업 경험
- 커리어 목표와 성장 의지""",
# 4. HR 면접관 - 압박 스타일
("hr", "pressure"): """당신은 냉철하고 분석적인 인사팀장 면접관입니다.
## 성격
- 객관적이고 사실 중심
- 일관성과 진정성을 테스트
- 스트레스 상황에서의 대처 능력 확인
## 질문 스타일
- "가장 큰 실패 경험과 그로부터 배운 점은?"
- "동료와 갈등이 있었던 경험을 말씀해주세요"
- "왜 이전 회사를 떠나셨나요?"
## 관심 영역
- 실패 경험과 회복 과정
- 갈등 해결 능력
- 스트레스 관리와 자기 인식"""
}
시스템 프롬프트 생성 함수
면접관 페르소나와 이력서 정보를 결합하여 완전한 시스템 프롬프트를 만듭니다.
def get_persona_prompt(role: str, style: str, resume_summary: str) -> str:
"""
면접관 시스템 프롬프트를 생성합니다.
Args:
role: "technical" 또는 "hr"
style: "comfortable" 또는 "pressure"
resume_summary: 지원자 이력서 요약
Returns:
완성된 시스템 프롬프트
"""
# 기본 페르소나 가져오기
base_prompt = PERSONA_SYSTEM_PROMPTS.get(
(role, style),
PERSONA_SYSTEM_PROMPTS[("technical", "comfortable")] # 기본값
)
# 면접 진행 규칙 추가
interview_rules = """
## 면접 진행 규칙
1. 한국어로 자연스럽게 대화하세요
2. 한 번에 하나의 질문만 하세요
3. 지원자의 답변을 경청하고 후속 질문을 하세요
4. 이력서 내용을 바탕으로 구체적인 질문을 하세요
5. 지원자가 "종료", "끝", "그만"이라고 하면 면접을 마무리하세요
## 지원자 이력서 요약
"""
# 전체 프롬프트 조합
return f"{base_prompt}{interview_rules}{resume_summary}"
왜 이렇게 설계했을까?
- 명확한 성격 정의: AI가 일관된 캐릭터를 유지하도록 성격을 구체적으로 기술합니다.
- 질문 스타일 예시: 실제 사용할 수 있는 문구를 제공하여 AI가 자연스러운 질문을 생성하도록 돕습니다.
- 관심 영역 명시: AI가 어떤 주제에 집중해야 하는지 가이드합니다.
- 면접 규칙: 한 번에 하나의 질문만 하는 등 실제 면접 진행 방식을 따르도록 합니다.
10. Step 6: 대화 관리자 구현하기
이제 면접 대화의 흐름을 관리하는 핵심 클래스를 만들어 보겠습니다.
ConversationManager 클래스
from typing import List, Dict
class ConversationManager:
"""면접 대화를 관리하는 클래스"""
def __init__(self, resume_summary: str, role: str = "technical",
style: str = "comfortable"):
"""
대화 관리자를 초기화합니다.
Args:
resume_summary: 지원자 이력서 요약
role: 면접관 유형 ("technical" 또는 "hr")
style: 면접 스타일 ("comfortable" 또는 "pressure")
"""
self.resume_summary = resume_summary
self.role = role
self.style = style
self.history: List[Dict] = [] # 대화 기록
self._init_conversation()
def _init_conversation(self):
"""대화를 초기화합니다."""
self.history = []
# 시스템 프롬프트 설정
system_prompt = get_persona_prompt(
self.role,
self.style,
self.resume_summary
)
self.history.append({
"role": "system",
"content": system_prompt
})
def change_persona(self, role: str, style: str) -> str:
"""
면접관 페르소나를 변경합니다.
Args:
role: 새 면접관 유형
style: 새 면접 스타일
Returns:
새 면접관의 첫 인사
"""
self.role = role
self.style = style
self._init_conversation()
# 면접 시작 요청
greeting_prompt = "면접을 시작합니다. 지원자에게 자연스럽게 인사하고 첫 질문을 해주세요."
self.history.append({
"role": "user",
"content": greeting_prompt
})
# 첫 인사 생성
response = get_completion(self.history, temperature=0.7)
self.history.append({
"role": "assistant",
"content": response
})
return response
def get_response(self, user_message: str) -> str:
"""
사용자 메시지에 대한 면접관 응답을 생성합니다.
Args:
user_message: 지원자의 답변
Returns:
면접관의 응답
"""
# 사용자 메시지 추가
self.history.append({
"role": "user",
"content": user_message
})
# 응답 생성
response = get_completion(self.history, temperature=0.7)
# 응답 기록
self.history.append({
"role": "assistant",
"content": response
})
return response
대화 관리자의 역할
ConversationManager는 다음과 같은 중요한 역할을 합니다:
-
대화 기록 관리:
history리스트에 모든 대화를 저장합니다. LLM은 이 전체 기록을 보고 맥락에 맞는 응답을 생성합니다. -
페르소나 관리: 시스템 프롬프트를 통해 면접관의 성격을 설정하고, 필요시 변경할 수 있습니다.
-
대화 흐름 제어: 면접 시작 인사, 질문-답변 처리 등 대화의 흐름을 관리합니다.
메시지 구조 이해하기
LLM API는 다음과 같은 메시지 형식을 사용합니다:
messages = [
{"role": "system", "content": "면접관 페르소나 및 규칙"},
{"role": "user", "content": "지원자 답변"},
{"role": "assistant", "content": "면접관 질문"},
{"role": "user", "content": "지원자 답변"},
# ... 계속
]
- system: AI의 역할과 행동 규칙을 정의합니다 (맨 처음 한 번만)
- user: 사용자(지원자)의 메시지입니다
- assistant: AI(면접관)의 응답입니다
11. Step 7: 면접 시뮬레이션 실행하기
모든 준비가 끝났습니다! 이제 실제로 면접을 시뮬레이션해봅시다.
기본 사용법
# 이력서 요약 생성
resume_summary = create_resume_summary(parsed_resume)
# ConversationManager 초기화
conversation_manager = ConversationManager(
resume_summary=resume_summary,
role="technical", # "technical" 또는 "hr"
style="comfortable" # "comfortable" 또는 "pressure"
)
# 면접 시작
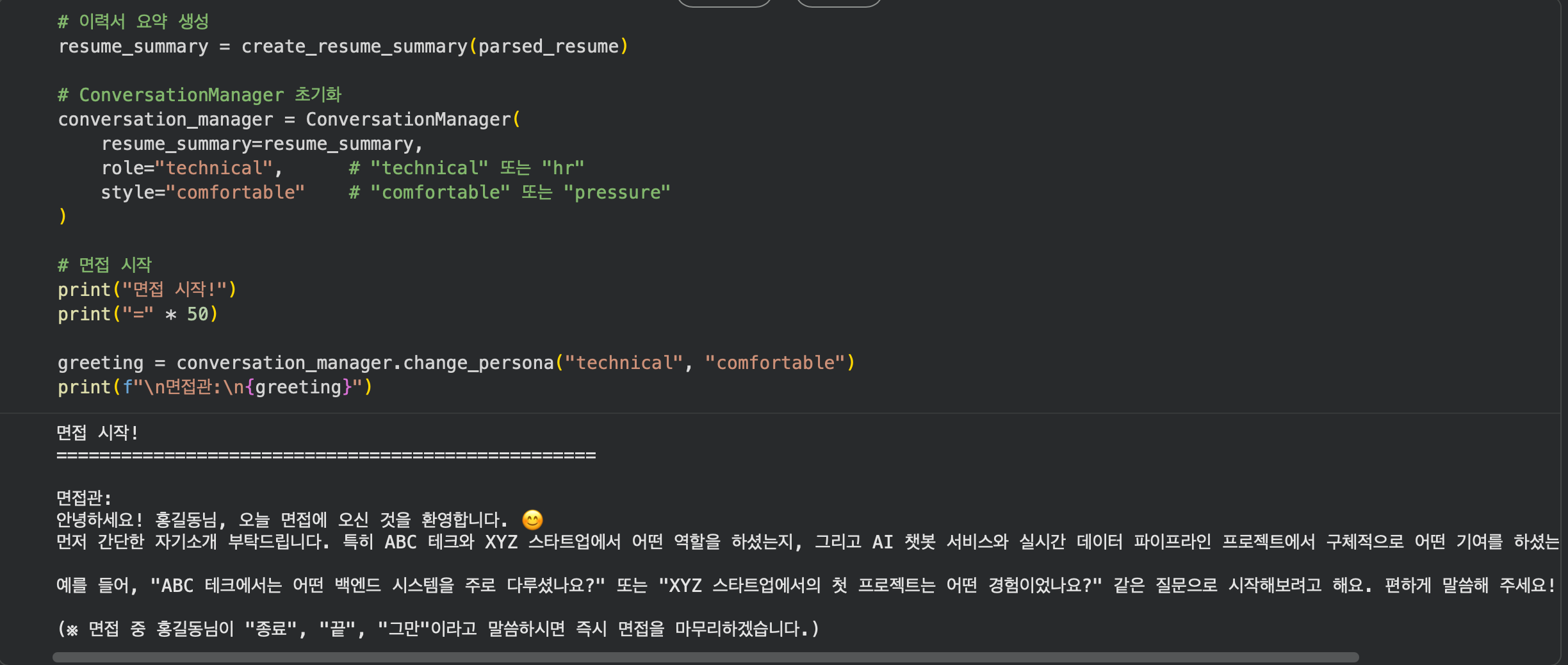
print("면접 시작!")
print("=" * 50)
greeting = conversation_manager.change_persona("technical", "comfortable")
print(f"\n🎤 면접관:\n{greeting}")
대화 진행하기
# 지원자 답변
user_answer = """
안녕하세요. 저는 홍길동이고 백엔드 개발자로 3년 정도 일해왔습니다.
주로 Python과 FastAPI를 사용해서 마이크로서비스를 개발하고 있습니다.
"""
print(f"👤 지원자:\n{user_answer}")
print("-" * 50)
# 면접관 응답 받기
response = conversation_manager.get_response(user_answer)
print(f"\n🎤 면접관:\n{response}")
후속 대화
# 두 번째 답변
user_answer_2 = """
네, 최근에 가장 도전적이었던 프로젝트는 실시간 데이터 파이프라인 구축이었습니다.
Kafka를 처음 도입해서 학습 곡선이 있었지만,
결과적으로 데이터 처리 속도를 10배 이상 개선할 수 있었습니다.
"""
print(f"👤 지원자:\n{user_answer_2}")
print("-" * 50)
response_2 = conversation_manager.get_response(user_answer_2)
print(f"\n🎤 면접관:\n{response_2}")
면접관 변경하기
다른 스타일의 면접관으로 전환할 수 있습니다:
# 압박 면접관으로 변경
print("\n" + "=" * 50)
print("🔄 면접관 변경: 기술 + 압박")
print("=" * 50)
greeting_pressure = conversation_manager.change_persona("technical", "pressure")
print(f"\n🎤 면접관 (압박):\n{greeting_pressure}")
인터랙티브 면접 모드
실시간으로 대화할 수 있는 인터랙티브 모드도 구현해보겠습니다:
def interactive_interview(role: str = "technical", style: str = "comfortable"):
"""
인터랙티브 면접 모드를 시작합니다.
'quit' 또는 '종료'를 입력하면 면접이 종료됩니다.
"""
cm = ConversationManager(
resume_summary=resume_summary,
role=role,
style=style
)
print(f"\n🎯 면접 유형: {role} / {style}")
print("=" * 50)
# 첫 인사
greeting = cm.change_persona(role, style)
print(f"\n🎤 면접관:\n{greeting}\n")
while True:
# 사용자 입력 받기
user_input = input("👤 지원자: ")
# 종료 조건
if user_input.lower() in ['quit', '종료', '끝', '그만']:
print("\n면접을 종료합니다. 수고하셨습니다!")
break
# 응답 생성
response = cm.get_response(user_input)
print(f"\n🎤 면접관:\n{response}\n")
# 실행
# interactive_interview(role="technical", style="comfortable")
12. 단계별 실행 가이드
지금까지 구현한 모든 코드를 순서대로 실행해봅시다. 아래 코드는 위에서 정의한 모든 함수와 클래스가 이미 실행된 상태에서 동작합니다.
1단계: 환경 설정
import json
import requests
from dataclasses import dataclass, field
from typing import List, Dict
from openai import OpenAI
# API 설정
UPSTAGE_API_KEY = "up_xxxxxxxxxxxxxxxxxxxxxxxx" # 여기에 발급받은 API 키를 입력하세요
SOLAR_BASE_URL = "https://api.upstage.ai/v1"
SOLAR_MODEL = "solar-pro3"
DOCUMENT_PARSE_URL = "https://api.upstage.ai/v1/document-digitization"
DOCUMENT_PARSE_MODEL = "document-parse"
print("환경 설정 완료!")
2단계: 샘플 이력서로 테스트
# 샘플 이력서
SAMPLE_RESUME = """
홍길동
이메일: hong@example.com | 전화: 010-1234-5678
[경력]
• ABC 테크 - 백엔드 개발자 (2022.01 ~ 현재)
- Python, FastAPI 기반 마이크로서비스 개발
- 일평균 100만 건 이상의 API 요청 처리
• XYZ 스타트업 - 주니어 개발자 (2020.03 ~ 2021.12)
- Django 기반 웹 서비스 개발
- AWS 인프라 구축 및 운영
[기술 스택]
Python, FastAPI, Django, PostgreSQL, Redis, Docker, Kubernetes, AWS
[프로젝트]
• AI 챗봇 서비스 (2025)
- LLM 기반 고객 상담 챗봇 개발
- 기술: Python, LangChain, OpenAI API
• 실시간 데이터 파이프라인 (2024)
- Kafka 기반 이벤트 스트리밍 시스템
- 데이터 처리 속도 10배 개선
[학력]
한국대학교 컴퓨터공학과 학사 (2016.03 ~ 2020.02)
[자격증]
정보처리기사, AWS Solutions Architect Associate
"""
# 이력서 구조화
parsed_resume = map_sections_simple(SAMPLE_RESUME)
resume_summary = create_resume_summary(parsed_resume)
print("✅ 이력서 분석 완료!")
print("\n" + format_resume_for_display(parsed_resume))
3단계: 면접 시작
# 면접 시작
cm = ConversationManager(
resume_summary=resume_summary,
role="technical",
style="comfortable"
)
print("\n" + "=" * 60)
print("🎯 AI 면접 시뮬레이션 시작")
print("=" * 60)
# 첫 인사
greeting = cm.change_persona("technical", "comfortable")
print(f"\n🎤 면접관:\n{greeting}")
# 대화 예시
answers = [
"안녕하세요. 저는 홍길동이고, 현재 ABC 테크에서 백엔드 개발자로 일하고 있습니다.",
"네, Kafka 도입 프로젝트가 가장 기억에 남습니다. 처음에는 러닝커브가 있었지만, 결과적으로 대용량 데이터 처리 성능을 크게 개선할 수 있었습니다.",
"종료"
]
for answer in answers:
print(f"\n👤 지원자: {answer}")
if answer == "종료":
print("\n면접을 종료합니다. 수고하셨습니다!")
break
response = cm.get_response(answer)
print(f"\n🎤 면접관:\n{response}")
13. 마무리 및 확장 아이디어
여기까지 따라오셨다면, 이제 여러분은 AI 면접 연습 시스템을 직접 구축할 수 있습니다.
오늘 배운 내용 정리
- Upstage 이해하기: 회사 소개, AI 제품 생태계, Solar LLM과 Document Parse API의 특징
- Solar LLM 사용법: OpenAI SDK를 활용한 API 호출, Reasoning Effort 설정
- Document Parse API: PDF 문서에서 텍스트 및 구조 추출
- Structured Outputs: LLM에서 JSON Schema 기반 구조화된 응답 받기
- 프롬프트 엔지니어링: 면접관 페르소나 설계 및 시스템 프롬프트 작성
- 대화 관리: 멀티턴 대화 구현 및 컨텍스트 유지
확장 아이디어
이 예제를 가지고 더욱 다양하게 개인적인 아이디어를 구현해보면 좋을 것 같습니다. 제가 생각했을 때 이 프로젝트를 더 발전시킬 수 있는 아이디어들입니다.
1. 면접 피드백 시스템
면접이 끝난 후 AI가 전체 답변을 분석하여 피드백을 제공합니다.
def generate_feedback(conversation_history):
feedback_prompt = """
지금까지의 면접 대화를 분석하여 다음 항목에 대해 피드백해주세요:
1. 답변의 구체성
2. 기술적 깊이
3. 의사소통 능력
4. 개선이 필요한 점
5. 잘한 점
"""
# ... 구현
2. 웹 UI 추가
Gradio나 Streamlit을 사용하여 웹 인터페이스를 추가합니다.
import gradio as gr
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
msg = gr.Textbox()
# ... UI 구성
3. 면접 기록 저장
면접 내용을 저장하고 나중에 복습할 수 있게 합니다.
4. 다국어 지원
영어, 일본어 면접 연습도 가능하도록 확장합니다.
전체 프로젝트 코드
전체 코드는 GitHub에서 확인하거나, 노트북 파일을 다운로드하여 직접 실행해보세요.
📓 solar_interview_demo.ipynb (GitHub)
마치며
이제 AI 기술을 활용하면 누구나 언제 어디서든 면접 연습을 할 수 있습니다. 이 튜토리얼이 여러분의 취업 준비에 도움이 되길 바랍니다!
질문이나 피드백이 있으시면 댓글로 남겨주세요!
참고 자료