
조달엔 프로젝트를 진행하면서 상호명을 입력하면 사업자가 드롭다운으로 나와 선택할 수 있도록 기능을 구현해야 했습니다.
상호명은 opn_std_scsbid_bidders 테이블의 bidprcCorpNm 컬럼에 저장되어 있습니다.
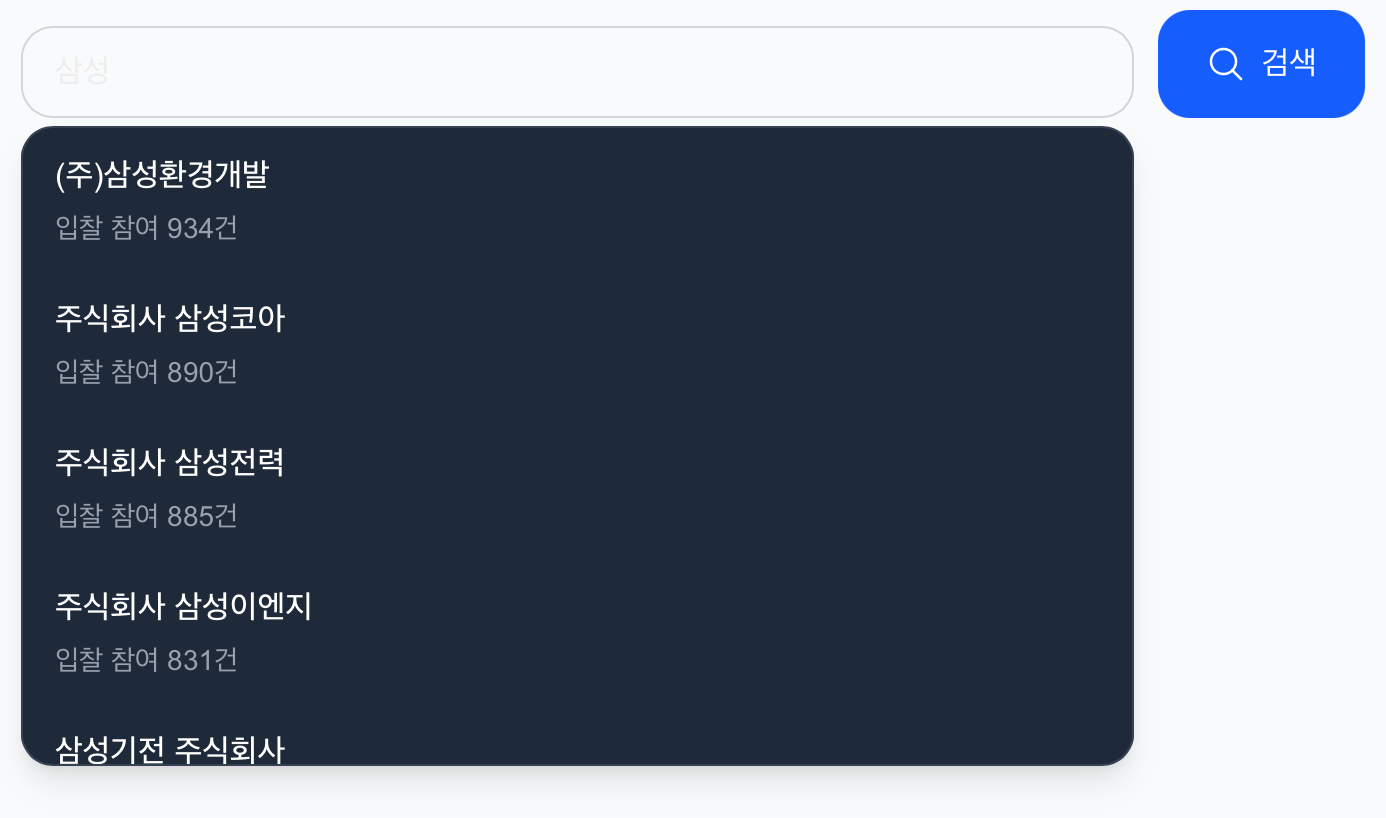
조건
- 테이블:
opn_std_scsbid_bidders(1,930만 행, 8095 MB) - 서버 사양: CPU 2vCPU, RAM 3.75GB
- 서비스: GCP Cloud SQL for PostgreSQL
LIKE 연산자 사용
우선 쿼리를 점진적으로 점검하면서 작성하기 위해 간단하게 LIKE 연산자를 사용하여 ‘삼성’이 포함된 상호명을 검색해보았습니다.
bidprcCorpNm 컬럼은 이미 인덱스를 사용하고 있습니다.
SELECT *
FROM opn_std_scsbid_bidders
WHERE "bidprcCorpNm" LIKE '%삼성%'
500 rows retrieved starting from 1 in 37 s 901 ms (execution: 37 s 428 ms, fetching: 473 ms)
EXPLAIN 으로 확인해보니 FULL SCAN 이 발생하고 있었습니다.

그룹화 및 카운트
화면과 같이 사업자 별 입찰 횟수를 표시하기 위해 사업자등록번호(bidprcCorpBizrno)로 그룹화하고 각 사업자의 입찰 횟수를 세어보았습니다.
SELECT "bidprcCorpBizrno",
COUNT(*) AS bidder_count
FROM opn_std_scsbid_bidders
WHERE "bidprcCorpNm" LIKE '%삼성%'
GROUP BY "bidprcCorpBizrno";
460 rows retrieved starting from 1 in 47 s 550 ms (execution: 47 s 149 ms, fetching: 401 ms)
무려 47초 가량이 소요되었습닌다.
와일드카드 위치 변경
%삼성% 에서 삼성% 으로 변경하여 앞부분 일치로 바꾸니 속도가 약간 빨라졌습니다.
SELECT "bidprcCorpNm", COUNT(*) as count
FROM opn_std_scsbid_bidders
WHERE "bidprcCorpNm" LIKE '삼성%'
GROUP BY "bidprcCorpNm"
ORDER BY count DESC
LIMIT ${limit};
20 rows retrieved starting from 1 in 16 s 65 ms (execution: 15 s 637 ms, fetching: 428 ms)

이번에는 Bitmap Index Scan 을 사용하였고 속도는 이전에 비해 절반 이상 단축되었지만 여전히 16초 가량으로 사용자에게 제공할 수는 없었습니다.
Materialized View 도입
이 상황에서 여러 방법이 있을 수 있겠지만 사용한 방법은 Materialized View 를 도입하는 것이었습니다.
Materialized View 는 쿼리 결과를 물리적으로 저장하는 뷰로, 복잡한 쿼리를 미리 계산해두고 빠르게 조회할 수 있도록 도와줍니다.
미리 계산하여 저장하기 때문에 실시간성을 요하는 데이터에는 적합하지 않지만, 입찰 이력과 같이 자주 변경되지 않는 데이터에는 매우 효과적입니다.
CREATE MATERIALIZED VIEW IF NOT EXISTS mv_business_bid_counts AS
SELECT
"bidprcCorpBizrno" as business_no,
(array_agg("bidprcCorpNm" ORDER BY "createdAt" DESC))[1] as business_name,
COUNT(*) as bid_count,
MAX("createdAt") as last_bid_date
FROM opn_std_scsbid_bidders
WHERE "bidprcCorpBizrno" IS NOT NULL
GROUP BY "bidprcCorpBizrno"
WITH DATA;
187,872 rows affected in 1 m 27 s 338 ms
뷰를 생성하는데 1분 30초 가량 소요가 되었습니다. 이렇게 뷰를 만들 때 소요 시간을 측정을 해야할 필요가 잇습니다.
이유는 뷰를 갱신할 때 참고할 수 있기 때문입니다. 에를 들어 1분 마다 데이터를 갱신한다고 했을 때 1분 30초 가량이 소요가 되면 갱신 주기를 늘려야 하기 때문입니다.
쿼리
FROM 절에 Materialized View 를 사용하도록 쿼리를 변경합니다.
SELECT business_no, business_name, bid_count
FROM mv_business_bid_counts
WHERE business_name LIKE '%삼성%'
ORDER BY bid_count DESC
LIMIT ${limit}
20 rows retrieved starting from 1 in 401 ms (execution: 22 ms, fetching: 379 ms)
응답 속도가 400ms 로 대폭 단축되었습니다. 더 자세히 보면 실행 시간은 22ms 로 매우 짧고, 데이터 페칭 시간이 379ms 로 대부분을 차지하고 있음을 알 수 있습니다.
fetching 은 이전 쿼리와 비슷하게 걸리고 실제로 데이터를 조회하는 시간은 매우 짧아진 것입니다.

서버 로그를 확인해보면 다음과 같이 응답이 매우 빨라진 것을 알 수 있습니다.
apps/api dev: [00:27:18] http [LoggingInterceptor] Response sent
apps/api dev: {
apps/api dev: "type": "RESPONSE",
apps/api dev: "requestId": "2d7321d4-132d-4b91-a7b3-27d7d8e58c0b",
apps/api dev: "method": "GET",
apps/api dev: "url": "/api/v1/bid-result/businesses/suggest?q=%EB%B6%80%EB%8F%99%EC%82%B0&limit=10%22",
apps/api dev: "statusCode": 200,
apps/api dev: **"duration": "13ms"**
apps/api dev: }