
목표
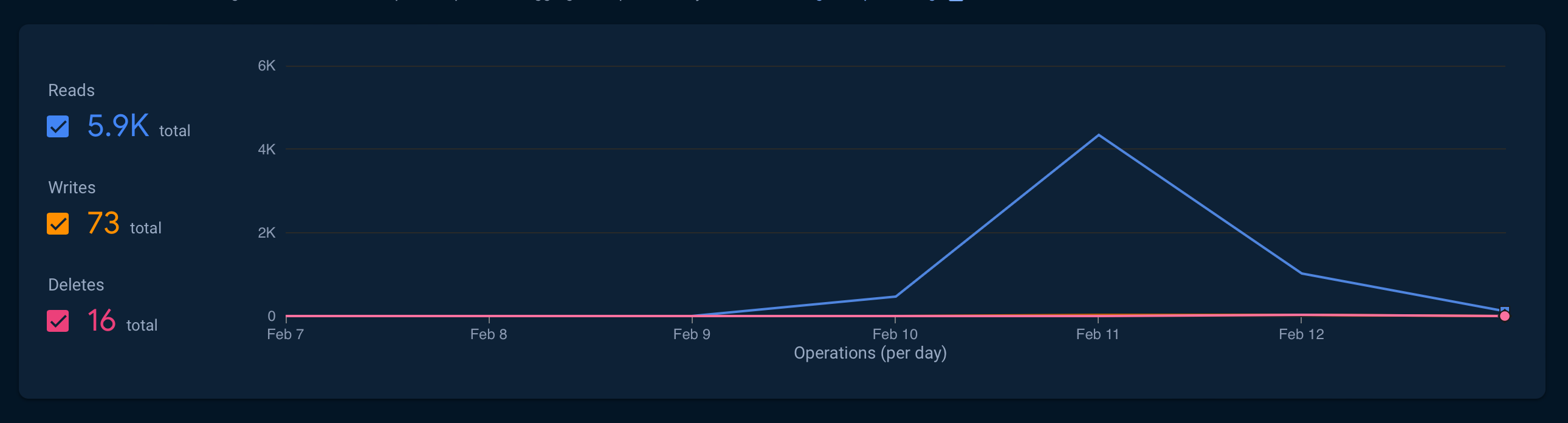
원픽 을 사이드 프로젝트로 만들어서 실사용을 하는데 firestore 사용량을 보니 6k 에 가까워졌다.
Firebase Pricing plans 를 보면 firestore 의 read 는 50k 까지 무료이다.
서비스를 사용하면서 한 달 치 원픽을 등록했을 뿐인데도 이와 같은 사용량이 나와서 계산을 해보았다.
상황
원픽 은 여정을 만들고 하루에 한 장 사진을 올리는 서비스이다.
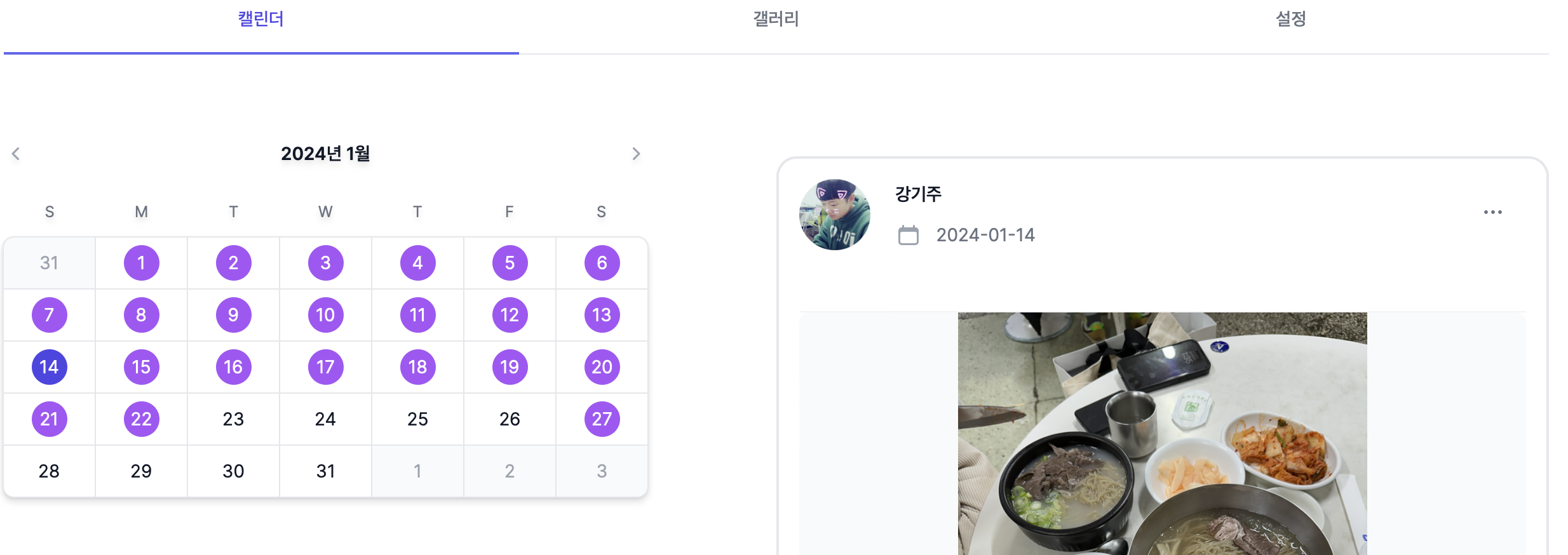
동작 방식을 간단히 설명하면 다음과 같다.
- 해당 월에 픽이 있으면 해당 일자에 보라색 원형으로 표시한다.
- 해당 일자를 선택하면 해당 일자에 등록된 픽을 보여준다.
- 픽을 클릭하면 픽의 상세 정보를 보여준다.
여정이 개인이 쓰면 간단한데 초대해서 여정을 공유할 수 있기 때문에 픽을 동기화 해야하는 기능이 필요했다. 그래서 픽을 등록하거나 캘린더의 일자를 선택해서 조회할 때마다 현재 보고 있는 캘린더의 월에 해당하는 픽을 모두 조회했다.
위 로직을 가지고 document read 를 구해보자.
30일 픽 등록
1월 1일 ~ 30일까지 픽을 등록을 가정하자
1일 선택 & 픽 등록
- 1월 픽 목록 조회 - 0 Read
- 1월 픽 목록 조회 - 1 Read
2일 선택 & 픽 등록
- 1월 픽 목록 조회 - 1 Read
- 1월 픽 목록 조회 - 2 Read
3일 선택 & 픽 등록
- 1월 픽 목록 조회 - 2 Read
- 1월 픽 목록 조회 - 3 Read
4일 선택 & 픽 등록
- 1월 픽 목록 조회 - 3 Read
- 1월 픽 목록 조회 - 4 Read
…
30일 선택 & 픽 등록
- 1월 픽 목록 조회 - 29 Read
- 1월 픽 목록 조회 - 30 Read
등록만 순차적으로 해도 840 Read 가 나온다.
30일 픽 조회
30개의 픽이 저장이 되고 사용자가 하루씩 선택하며 조회를 한다고 가정하자.
30 일 * 30 Read = 900 Read
시나리오 결론
30일을 픽을 등록하고 30일을 조회하면 1740 Read 가 나온다. 이 수치는 최소이다. 이유는 여정을 공유해서 여러명이 픽을 등록하고 조회할 수 있기 때문이다.
개선 방법
현 구조에서 개선을 해보자
방법1 - Pick Subscribe 하기
Get realtime updates with Cloud Firestore 을 참고해서 onSnapshot 을 사용하면 데이터가 변경된 것을 알 수 있다.
이 방법을 선택할 경우 캘린더 일자를 변경할 때마다 픽을 조회하는 방식을 사용하지 않을 수 있다. 그러나 pick collection 을 구독할 경우 모든 데이터를 불러오게 된다. 그래서 월별로 조회하여 구독하게 되면 캘린더에서 월을 변경할 때마다 구독을 해제하고 다시 구독하거나 구독의 개수를 계속해서 늘려나가게 된다.
방법2 - 데이터 구조 변경
Realtime updates 를 사용하는 것은 방법1 과 같지만 대상이 다르다.
현재 데이터 구조는 아래와 같이 되어 있다.
itineraries : collection - picks : subcollection
이때 pickDates 라는 필드를 추가하게 되면 itinerary 1개의 document 만 조회하면 캘린더에 표시할 수 있는 픽을 모두 조회할 수 있다. 즉 불필요한 read 가 발생하지 않는다.
만약 픽이 등록되거나 삭제되었을 때 itinerary 의 pickDates 가 달라질 경우 modified event 로 값을 알려주기 때문에 간단하게 값을 변경해주면 된다.
이 구조를 떠올리고 보니 캘린더는 날짜만 필요했을 뿐인데 픽의 정보를 모두 조회하고 있었다.
변경 후 사용량
위에서 가정했던 같은 상황으로 비교해보자.
30일 픽 등록
여정 조회 : 30 Read (구독한 itinerary 가 계속 값이 바뀌었다고 알려주기 때문)
픽 조회 : 30 Read
30일 픽 조회
30일 * 1 Read = 30 Read
총 60 Read 가 나온다.
이 수치는 1740 Read 에서 60 Read 로 줄어든다. 수치로는 96% 가량 줄어든다.
결론
사실 이런 개선이 필요 없도록 설계하는 것이 맞지만 몸소 느끼고 경험해보니 더욱 몸에 와 닿았다. 이런 경험을 하기 위해 사이드를 만드는 것이기도 하고 또 다음에 만들 때는 더 좋은 구조로 만들 수 있겠다는 생각이 든다.
이번 경험은 알고리즘 문제를 푸는 것과 비슷한 느낌이였는데 비효율적인 계산에서 관점을 바꾸니 효율적인 계산이 가능해졌다.