목표
Spring 내에서 데이터를 캐싱하여 성능을 향상시키기
Cache 방법
Redis 를 사용해서 저장하는게 가장 좋겠지만 규모가 작기에 Redis 를 사용하기에는 오히려 적절하지 않다고 판단했다. 지금은 단순히 데이터를 캐싱하는 것이기 때문이다. 그래서 간단한 방법으로 Spring 내에서 캐싱을 하기로 하였다.
캐시 설정
CacheMap 이라는 클래스를 만들어서 사용하였다. 무한정 저장은 할 수 없어서 우선 1000개까지만 저장하도록 설정하였다.
import org.springframework.stereotype.Component;
import java.util.HashMap;
@Component
public class CacheMap {
HashMap<String, Object> cacheMap = new HashMap<>();
int maxStoreSize = 1000;
public void put(String key, Object value) {
if (maxStoreSize <= cacheMap.size()) {
this.pop();
}
cacheMap.put(key, value);
}
public Object get(String key) {
return cacheMap.get(key);
}
public boolean has(String key) {
return cacheMap.containsKey(key);
}
public void remove(String key) {
cacheMap.remove(key);
}
public void clear() {
cacheMap.clear();
}
public void pop() {
cacheMap.remove(cacheMap.keySet().stream().findFirst().get());
}
public void removesByPrefix(String prefix) {
cacheMap.entrySet().removeIf(entry -> entry.getKey().startsWith(prefix));
}
public int size() {
return cacheMap.size();
}
}
간단히 테스트 코드를 작성하였다.
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class CacheMapTest {
CacheMap cacheMap = new CacheMap();
@Test
void put() {
cacheMap.put("key", "value");
assertEquals("value", cacheMap.get("key"));
}
@Test
void put_1001() {
for (int i = 0; i < 1001; i++) {
cacheMap.put("key" + i, "value" + i);
}
assertEquals(1000, cacheMap.size());
}
@Test
void get() {
cacheMap.put("key", "value");
assertEquals("value", cacheMap.get("key"));
}
@Test
void has() {
cacheMap.put("key", "value");
assertTrue(cacheMap.has("key"));
assertNull(cacheMap.get("key1"));
}
@Test
void remove() {
cacheMap.put("key", "value");
cacheMap.remove("key");
assertNull(cacheMap.get("key"));
}
@Test
void clear() {
cacheMap.put("key", "value");
cacheMap.put("key1", "value2");
cacheMap.clear();
assertNull(cacheMap.get("key"));
assertNull(cacheMap.get("key1"));
}
@Test
void pop() {
cacheMap.put("key", "value");
cacheMap.put("key1", "value2");
cacheMap.pop();
assertNull(cacheMap.get("key1"));
}
@Test
void removesByPrefix() {
cacheMap.put("k-1", "value");
cacheMap.put("y-1", "value2");
cacheMap.removesByPrefix("k");
assertNull(cacheMap.get("k-1"));
assertEquals("value2", cacheMap.get("y-1"));
}
}
캐시 사이즈 계산
막연한 1000개가 아니라 평균 데이터 양을 확인해서 적절한 사이즈를 설정해야 한다. /?page=0, /?page=1, /?page=2, …, /?page=9 까지 요청해서 저장된 데이터를 확인하였다. 즉 총 10건의 질의 결과를 저장하였다.

Retained 이 약 500kb 정도로 나왔다.
10건 - 500kb 1000건 - 50mb 2000건 - 100mb 4000건 - 200mb
서버 용량이 1GB 로 기본 사용량이 350MB 정도 되니 200MB 는 사용할 수 있다고 판단하였다.
그래서 CacheMap 의 maxStoreSize 를 4000 으로 설정하였다.
테스트
코드 적용
데이터를 불러오는 곳은 Service 에서 캐싱하고 캐싱된 값을 사용하도록 하였다.
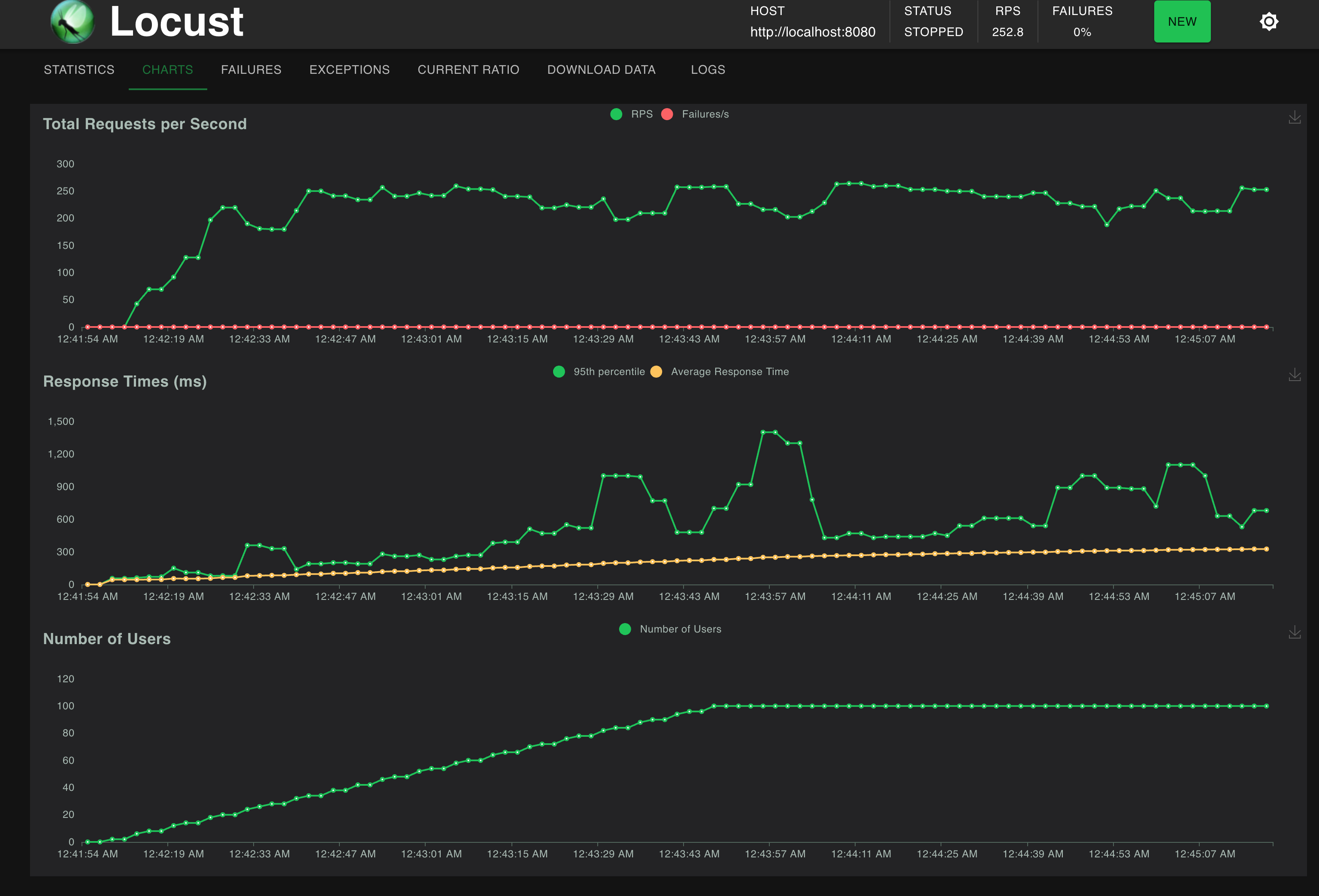
성능 테스트 결과
동시 사용자가 100명이 되어도 RPS(초당 요청 수) 가 250 정도로 유지되었다. 이는 DB 서버 Scale Up 에서 80 정도였다. 즉 80 -> 250 으로 성능이 향상되었다. 대략 300% 정도 성능이 향상되었다고 볼 수 있다. 그렇지만 Response Time 의 차트를 보면 낮은 기울기지만 계속해서 증가하는 것을 볼 수 있다.