
해결 방법
풀 스캔하는 쿼리를 찾아 인덱스 사용하면 된다.
문제 상황
개인적으로 사용하는 서버가 Dedicated 와 Serverless 각각 하나씩 사용하고 있다. Dedicated 서버는 M2 타입으로 대략 월 \$9 에 사용하고 Serverless 는 기본 제공 사용량 살짝 넘어 과금이 $1~2 달러 수준이었다.
휴대폰에 결제 문제가 왔는데 약 $24 가 결제가 되어있어 금액보다는 무엇 때문에 더 청구 되었는지가 더 궁금하고 이상했다.

위 사진에서 볼 수 있듯이 RPU 사용량이 많아 그에 맞는 가격이 청구가 되었다.
RPU(Read Processing Unit ) 는 개별 document 를 읽을 때마다 1씩 증가하는 값이다.
해결 과정
원인 파악
우선 막연하게 생각을 했을 때 의문이 드는 부분은 주로 내가 거의 이용하는 서비스인데 왜 사용량이 많이 올랐을까 하는 것이였다.
강하게 의심이 가는 부분이 있었는데 앱에서 앨범 목록을 5초 간격으로 주기적으로 불러와 업데이트하도록 만들어 놓았었다. PC emulator 가 계속 켜져있어서 계속해서 업데이트가 된 것이 화두일 것이라는 생각이 들었다. 무엇보다 일자별 사용량을 보니 몇 개의 날만 비정상적으로 많았기 때문이다.
문제가 될 것으로 판단된 해당 쿼리를 찾아 explain 하였다.
explain 은 쿼리 실행 과정을 보여주는 명령어이다.
예를 들어 몇 개의 document 를 찾고 그 중에서 몇 개의 document 를 반환했는지, index 는 무엇을 사용했는지 등 많은 정보를 알려준다.
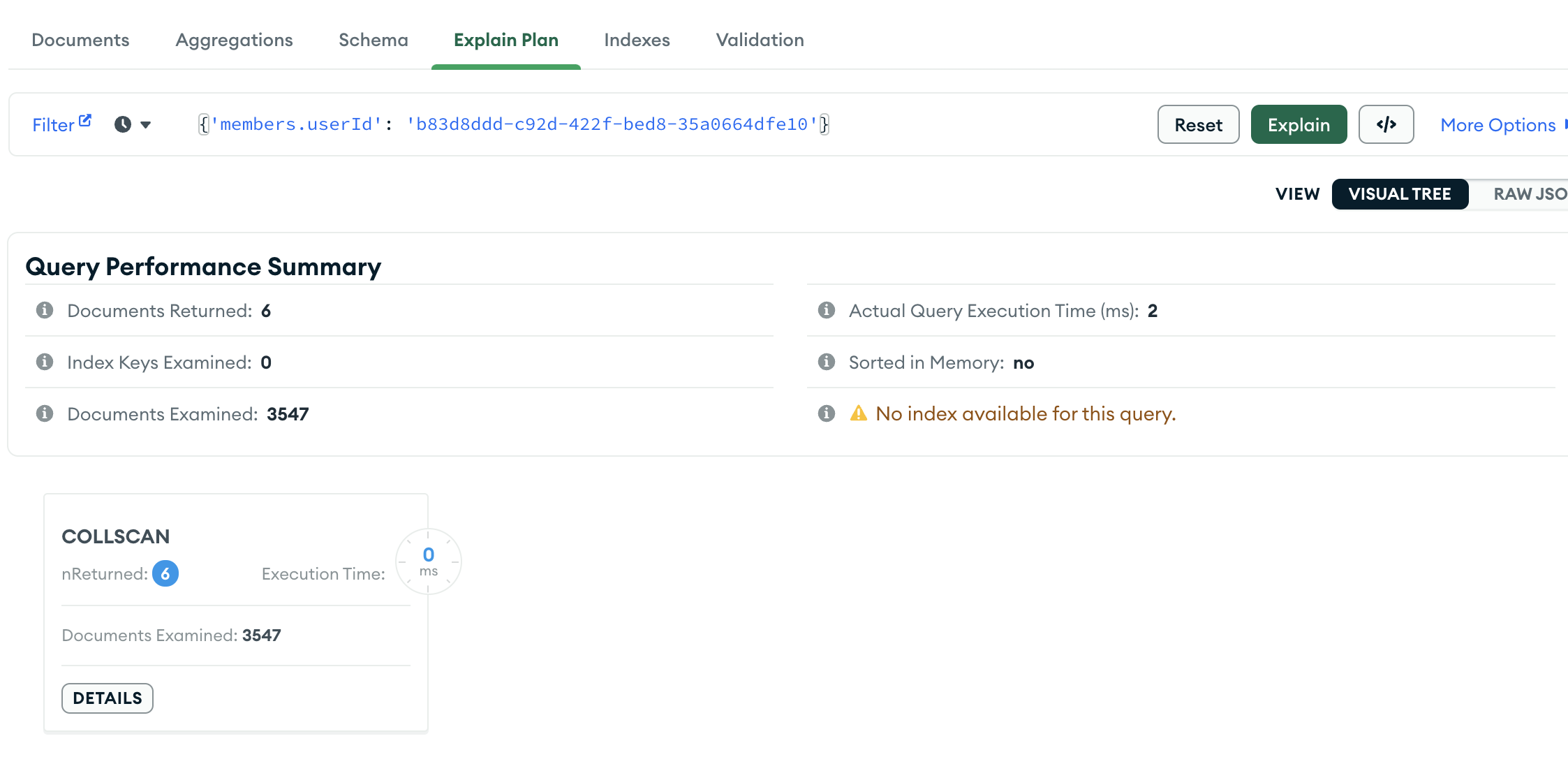
기존 쿼리를 실행해보니 userId 를 기준으로 앨범을 찾는데 document 를 약 3500개를 거쳐서 6개를 가져왔다. 3500개는 해당 collection 의 전체 document 수이다. 즉 full scan 을 한 것이다.
5초마다 실행되었으니 이를 계산해보면 아래와 같다. 1분에 12번 실행되고 1시간에 720번 실행되고 6시간이면 4320번 실행된다. 한 번의 쿼리마다 3500개의 document 를 탐색하니 4320 * 3500 = 15,120,000 이다. 즉 6시간이면 천오백만 개의 document 를 탐색하는 것이다. 이보다 더 길거나 여러 날도 이와 같다고 보면 청구 되었던 1억 6천만개의 document 조회가 납득이 된다..
해결 작업
index 추가
해당 collection 은 개별 id 또는 userId 를 기준으로 조회가 될 것이기 때문에 index 에 userId 로 추가하였다. 물론 command 가 아닌 서버 환경에서 설정하도록 하였다. command 로 할 경우 서버가 변경될 때 놓칠 수 있기 때문이다.
index 추가 후 조회 결과
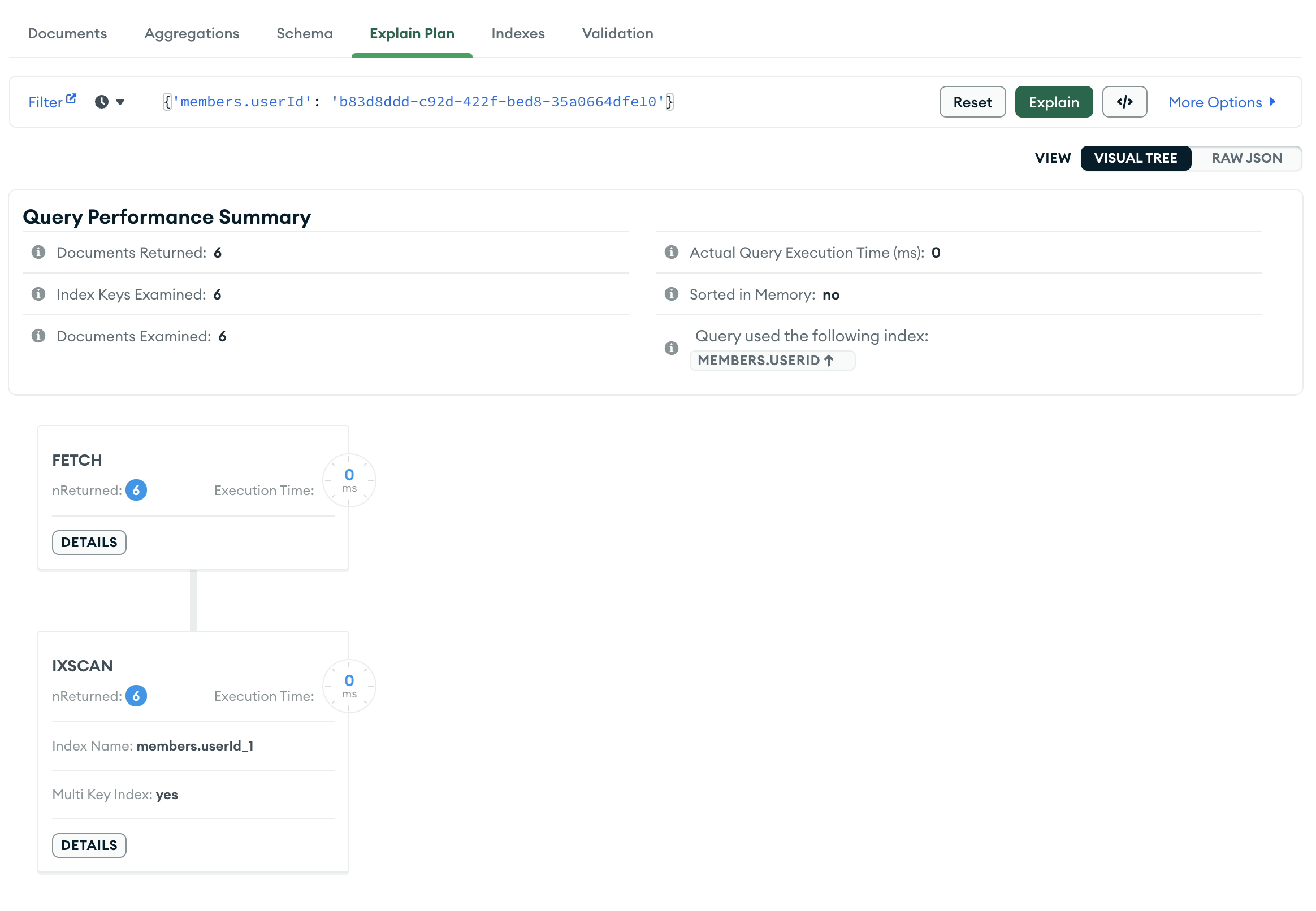
index 를 적용하였더니 document 6번 탐색해서 6개의 document 를 반환한다. 즉 가장 완벽한 조회이다.
이와 같은 변화는 Query used the following index 를 보면 확인할 수 있다. 처음에는 No index available for query 라고 나왔지만 index 를 추가한 후에는 MEMBERS.USERID 를 사용했다고 나타내주고 있다.
index 여부에 따라 document 탐색 과정도 달라지는 것도 확인해볼 수 있다.
index 사용 전에는 COLLSCAN 이라고 나오는데 이는 collection scan 을 의미한다. 즉 collection 을 처음부터 끝까지 탐색하는 것을 의미한다.
index 사용 후에는 IXSCAN 이라고 나오는데 이는 index scan 을 의미한다. 즉 index 를 사용하여 document 를 찾는 것을 의미한다.
결론
인덱스 개념을 몰랐던 것은 아니고 오히려 최적화와 관련된 부분도 글로 배워 알고있었지만 사용량이 적다는 이유로 너무 무심했다. 방치했던 비효율이 눈덩이처럼 서서히 커지면 감당 못할만큼 커질 수 있다는 점에서 놀라기도 하였다. 하지만 개인적으로 튜닝을 접할 기회가 별로 없어 아쉬웠던 나에게는 2만원 덕분에 나름 값진 경험을 하였다.
여러모로 비교하고 테스트하는 과정에서 재밌고 신선해서 오히려 좋은 기억이고 경험이 되었다.