순위 검색
문제 설명
- 지원서 선택한 정보를 가지고 지원자들 중에서 특정 조건을 만족하는 사람의 수를 구하라.
- 선택 정보는 아래와 같다.
- cpp, java, python
- backend, frontend
- junior, senior
- chicken, pizza
흐름 파악
흐름 파악을 위해 꼬리에 꼬리를 무는 방식으로 접근하려한다.
조건에 만족하는 사람 어떻게 구해?
선택 사항에 만족하면서 점수가 X 이상인 사람을 구하면 돼.
선택 사항에 만족하는 사람 구하는 방법은?
query 에서 선택 사항 중 하나를 선택하고, 선택 사항이 ‘-‘ 이면 모든 선택 사항을 선택하면 돼.
점수가 X 이상인 사람 구하는 방법은?
query 에서 선택사항에 해당하는 사람의 점수를 추출해서 X 이상인 사람을 구하면 돼.
시각화
신청자 정보가 아래와 같다고 하자.

이 때 선택사항 별로 분류를 해보면 아래와 같다.
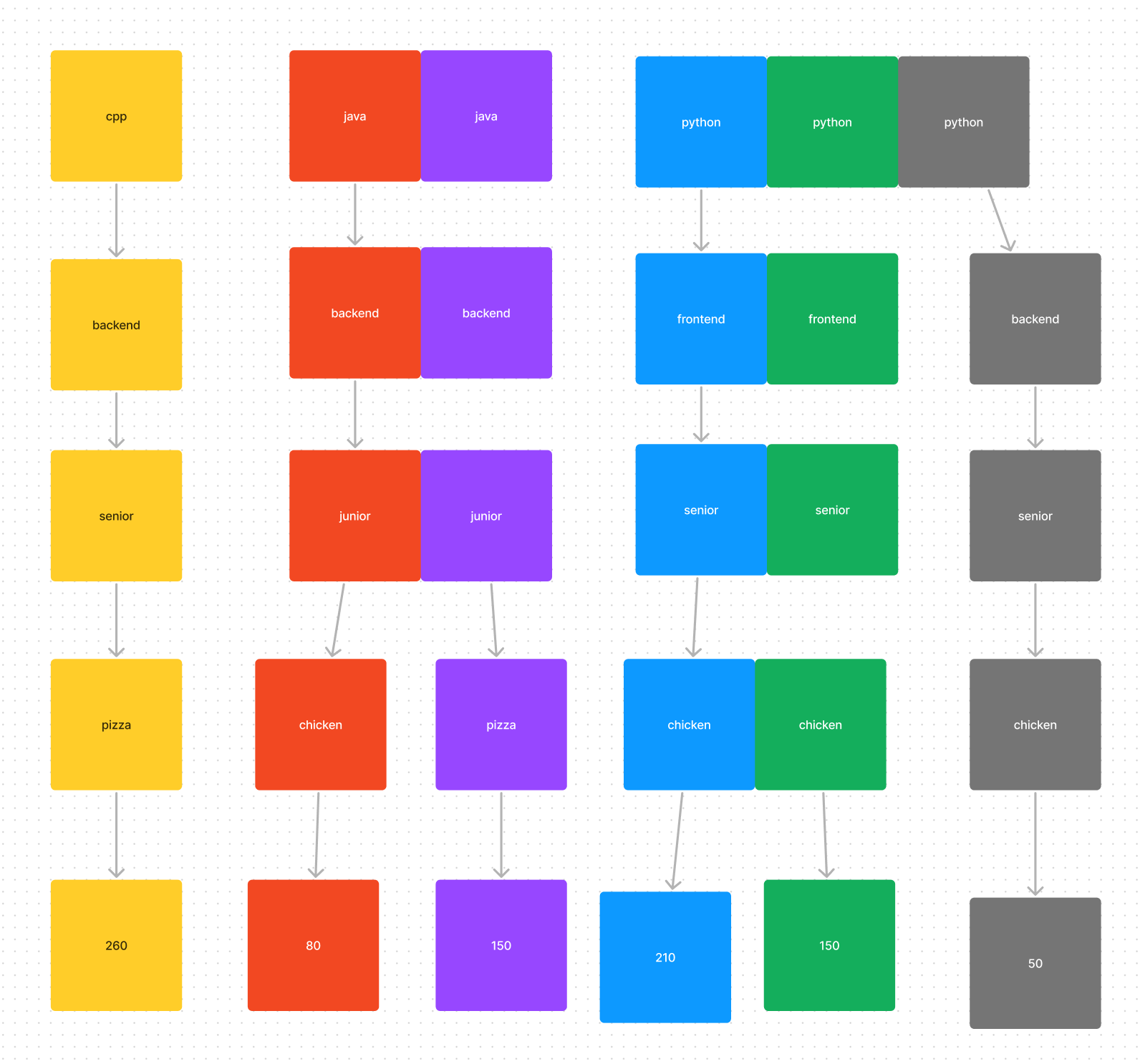
python, frontend, senior, chicken 을 선택했을 때는 아래와 같이 분류할 수 있다. frontend 를 선택했기 때문에 backend 는 제외된다.
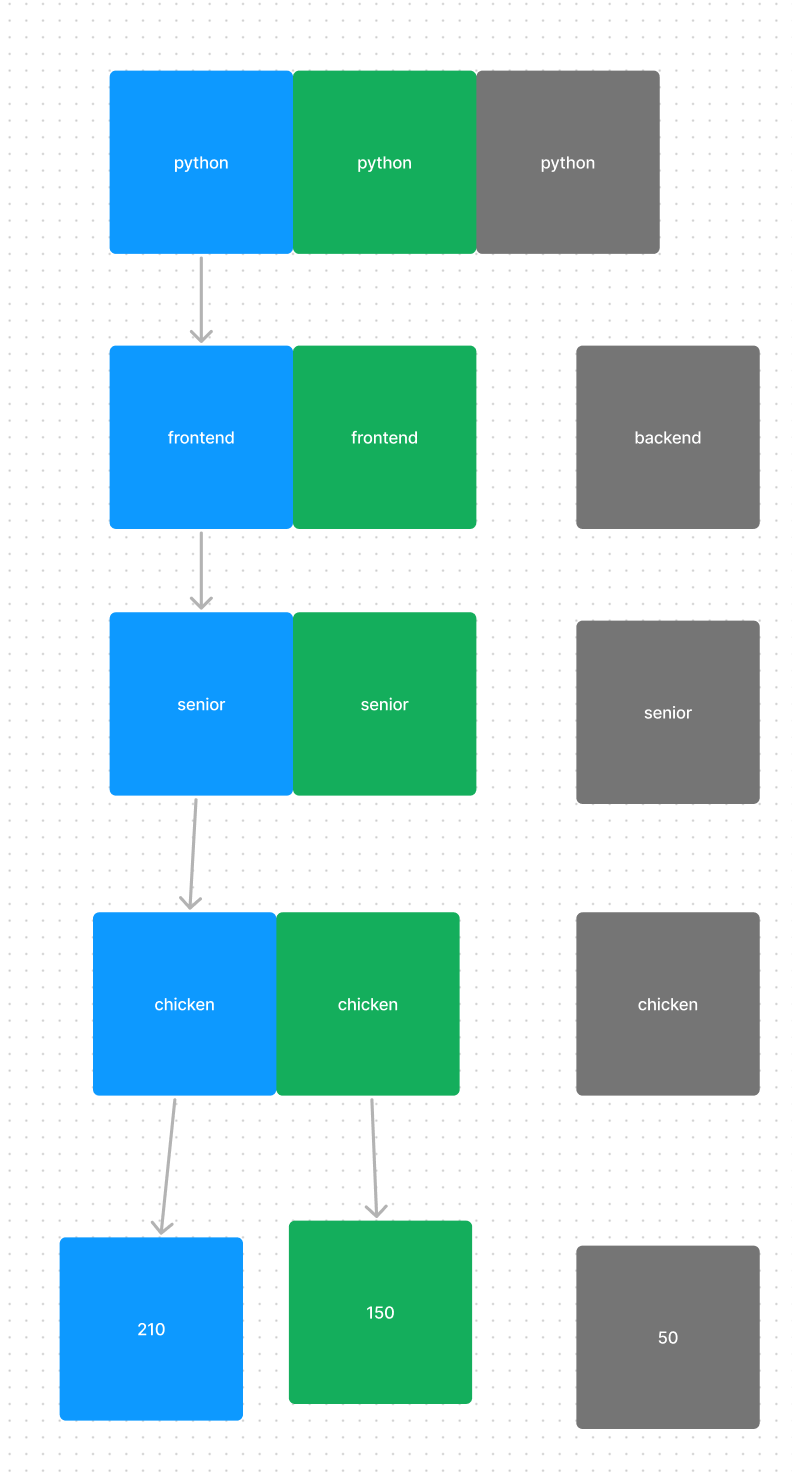
python, - (모두 선택), senior, chicken 을 선택했을 때는 아래와 같이 분류할 수 있다. 즉 점수를 모두 가져오면 210, 150, 50 이 된다.
이를 논리적으로 보면 아래와 같이 볼 수 있다.
- python, -, senior, chicken
위 조건을 펼쳐보면 아래와 같이 2개의 조건으로 볼 수 있다.
- python, frontend, senior, chicken
- python, backend, senior, chicken
시간 초과
위와 같은 논리로 조건 중에서 - 가 있을 경우에는 모든 조건을 선택한 것으로 볼 수 있다. 이와 같이 코드를 작성해도 코드를 제출해보면 효율성 테스트에서 시간초과가 발생한다.
어떻게 하면 시간을 줄일 수 있을까?
조금 더 생각해보면 테스트 케이스의 최대 query 행 개수는 100,000 개이다. 그러기에 query 부분에서 점수를 제외하면 겹치는 조건이 대부분일 것이다.
그러므로 query 에 해당하는 점수 list 를 따로 저장하고 있다가 사용하도록 하면 된다. 점수를 구하는 과정에 제일 시간이 많이 걸리기 때문이다.
전체 코드
from bisect import bisect_left
from collections import defaultdict
def solution(infos, queries):
answer = []
info_dict = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(list))))
scores_dict = defaultdict(list)
select_dict = {
0: [['java'], ['cpp'], ['python']],
1: [['backend'], ['frontend']],
2: [['junior'], ['senior']],
3: [['chicken'], ['pizza']]
}
for info in infos:
chunks = info.split(" ")
info_dict[chunks[0]][chunks[1]][chunks[2]][chunks[3]].append(int(chunks[4]))
for query in queries:
query = [chunk for chunk in query.split(" ") if chunk != 'and']
search = []
for i, q in enumerate(query):
arr = []
if q != '-':
if not search:
search = [[q]]
continue
for s in search:
arr.append(s + [q])
if q == '-':
if i == 0 and not search:
search = select_dict[0]
continue
for s in search:
for select in select_dict[i]:
arr.append(s + select)
search = arr
scores = []
if ''.join(query[0:4]) in scores_dict:
scores = scores_dict[''.join(query[0:4])]
if not scores:
for s in search:
scores.extend(info_dict[s[0]][s[1]][s[2]][s[3]])
scores = scores if ''.join(query[0:4]) in scores_dict else sorted(scores)
count = len(scores) - bisect_left(scores, int(search[0][4]))
if ''.join(query[0:4]) not in scores_dict:
scores_dict[''.join(query[0:4])] = scores
answer.append(count)
return answer
info = ["java backend junior pizza 150" for i in range(50000)]
query = ["- and - and - and - 150" for i in range(100000)]
print(solution(info, query))
print(solution(
[
"java backend junior pizza 150",
"python frontend senior chicken 210",
"python frontend senior chicken 150",
"cpp backend senior pizza 260",
"java backend junior chicken 80",
"python backend senior chicken 50"
], [
"java and backend and junior and pizza 100",
"python and frontend and senior and chicken 200",
"cpp and - and senior and pizza 250",
"- and backend and senior and - 150",
"- and - and - and chicken 100",
"- and - and - and - 150"
]), [1, 1, 1, 1, 2, 4])